health strategy journal
management, engineering and
technology review
Joaquim Cardoso MSc.
Chief Research Officer (CRO); Chief Editor;
Chief Strategy Officer (CSO) and Senior Advisor
July 30, 2023

Scaling TransNormer to 175 Billion Parameters
Authors & Affiliations
2 Zhen Qin♯ , 1,2 Dong Li♯ , 1,2 Weigao Sun♯ , 1,2 Weixuan Sun♯ , 1,2 Xuyang Shen♯ , 2 Xiaodong Han, 2 Yunshen Wei, 2 Baohong Lv, 1 Fei Yuan, 2 Xiao Luo, 1 Yu Qiao, 1,2 Yiran Zhong∗
1S hanghai AI Laboratory,
2OpenNLPLab
The paper introduces and highlight the features and advantages of TransNormerLLM, an improved linear attention-based Large Language Model (LLM).
The authors emphasize that TransNormerLLM outperforms conventional softmax attention-based models in terms of both accuracy and efficiency.
They present various modifications and innovations incorporated into TransNormerLLM to achieve these improvements, such as positional embedding, linear attention acceleration, gating mechanism, tensor normalization, and Lightning Attention technique.
The paper also emphasizes the scalability of the model, making it suitable for deployment on large-scale clusters and facilitating the expansion to even more extensive models while maintaining outstanding performance metrics.
TransNormerLLM is positioned as an advanced and efficient model for LLMs, consistently outperforming Transformers in both accuracy and efficiency, with potential scalability up to 175 billion parameters.
Executive Summary
The authors present TransNormerLLM, the first linear attention-based Large Language Model (LLM) that outperforms conventional softmax attention-based models in terms of both accuracy and efficiency.
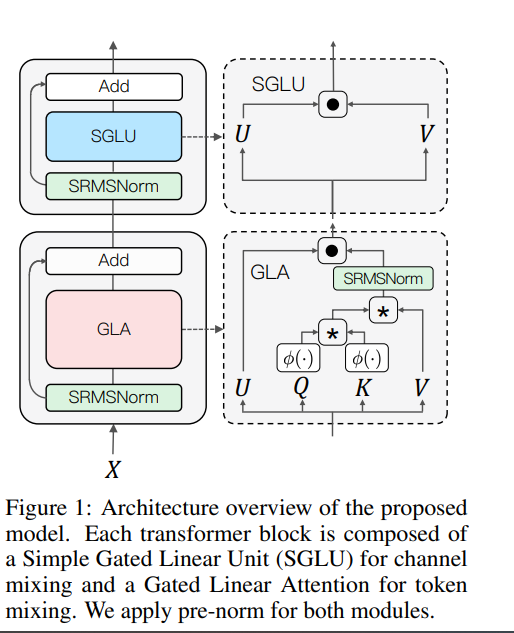
TransNormerLLM evolves from the previous linear attention architecture TransNormer [32] by making advanced modifications that include positional embedding, linear attention acceleration, gating mechanism, tensor normalization, and inference acceleration and stabilization.
Specifically, we use LRPE [34] together with an exponential decay to avoid attention dilution issues while allowing the model to retain global interactions between tokens.
Additionally, we propose Lightning Attention, a cutting-edge technique that accelerates linear attention by more than twice in runtime and reduces memory usage by a remarkable four times.
To further enhance the performance of TransNormer, we leverage a gating mechanism to smooth training and a new tensor normalization scheme to accelerate the model, resulting in an impressive acceleration of over 20%.
Furthermore, we have developed a robust inference algorithm that ensures numerical stability and consistent inference speed, regardless of the sequence length, showcasing superior efficiency during both training and inference stages.
Scalability is at the heart of our model’s design, enabling seamless deployment on large-scale clusters and facilitating expansion to even more extensive models, all while maintaining outstanding performance metrics.
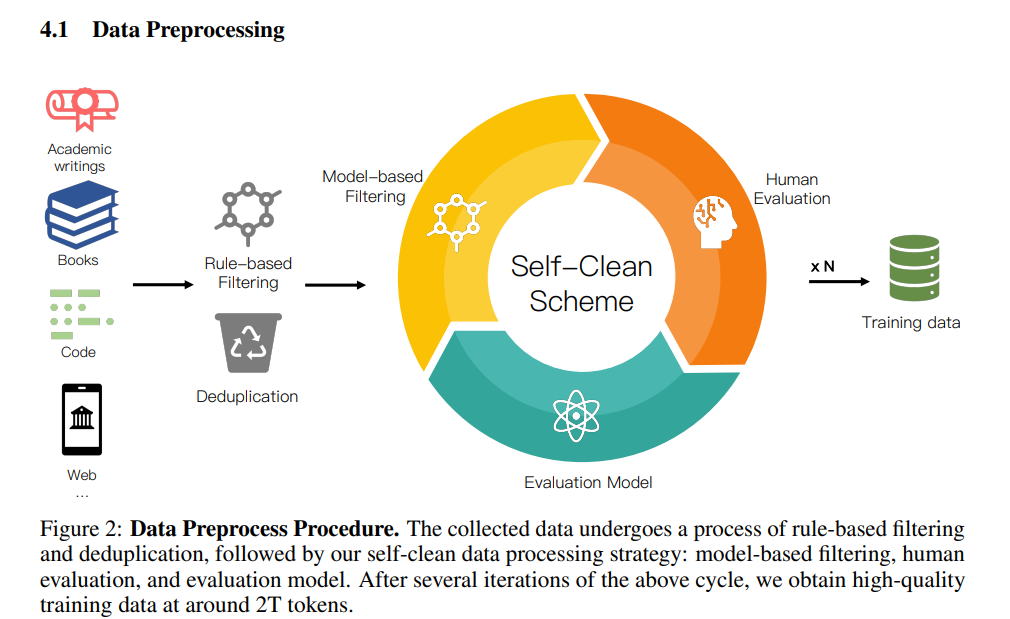
Rigorous validation of our model design is achieved through a series of comprehensive experiments on our self-collected corpus, boasting a size exceeding 6TB and containing over 2 trillion tokens.
To ensure data quality and relevance, we implement a new self-cleaning strategy to filter our collected data. we plan to open-source our pre-trained models, fostering community-driven advancements in the field and positioning our work as a stepping-stone toward exploring efficient transformer structures in LLMs
Conclusion
We introduced TransNormerLLM in this paper, an improved TransNormer that is tailored for LLMs.
Our TransNormerLLM consistently outperformed Transformers in both accuracy and efficiency and can be effectively scaled to 175 billion parameters.
Extensive ablations demonstrate the effectiveness of our modifications and innovations in position encoding, gating mechanism, activation functions, normalization functions, and lightning attentions.
To support the training of TransNormerLLM, we collected a large corpus that exceeds 6TB and contains over two trillion tokens.
- A novel self-clean strategy was utilized to ensure data quality and relevance.
Our pre-trained models will be released to foster community advancements in efficient LLM.
Infographic
Authors & Affiliations
2 Zhen Qin♯ , 1,2 Dong Li♯ , 1,2 Weigao Sun♯ , 1,2 Weixuan Sun♯ , 1,2 Xuyang Shen♯ , 2 Xiaodong Han, 2 Yunshen Wei, 2 Baohong Lv, 1 Fei Yuan, 2 Xiao Luo, 1 Yu Qiao, 1,2 Yiran Zhong∗
1S hanghai AI Laboratory,
2OpenNLPLab