




the health strategist
review
management, engineering and
technology review
Joaquim Cardoso MSc.
Chief Research Officer (CSO), Chief Editor
Chief Strategy Officer (CSO) and Senior Advisor
August 1st, 2023
What’s the key message?
Machine learning (ML) algorithms present a promising alternative and a potential game changer to speed up and automate the sistematic reviews process.
Key Takeaways:
Background
- Within evidence-based practice (EBP), systematic reviews (SR) are considered the highest level of evidence in that they summarize the best available research and describe the progress in a determined field.
- Due its methodology, SR require significant time and resources to be performed; they also require repetitive steps that may introduce biases and human errors.
- Machine learning (ML) algorithms therefore present a promising alternative and a potential game changer to speed up and automate the SR process.
- This review aims to map the current availability of computational tools that use ML techniques to assist in the performance of SR, and to support authors in the selection of the right software for the performance of evidence synthesis.
Methods
- The mapping review was based on comprehensive searches in electronic databases and software repositories to obtain relevant literature and records, followed by screening for eligibility based on titles, abstracts, and full text by two reviewers.
- The data extraction consisted of listing and extracting the name and basic characteristics of the included tools, for example a tool’s applicability to the various SR stages, pricing options, open-source availability, and type of software. These tools were classified and graphically represented to facilitate the description of our findings.
- A total of 9653 studies and 585 records were obtained from the structured searches performed on selected bibliometric databases and software repositories respectively.
- After screening, a total of 119 descriptions from publications and records allowed us to identify 63 tools that assist the SR process using ML techniques.
Conclusions
This review provides a high-quality map of currently available ML software to assist the performance of SR. ML algorithms are arguably one of the best techniques at present for the automation of SR.
The most promising tools were easily accessible and included a high number of user-friendly features permitting the automation of SR and other kinds of evidence synthesis reviews.
DEEP DIVE
Machine learning computational tools to assist the performance of systematic reviews: A mapping review [excerpt]
Ramon Cierco Jimenez, Teresa Lee, Nicolás Rosillo, Reynalda Cordova, Ian A Cree, Angel Gonzalez & Blanca Iciar Indave Ruiz
August 1st, 2023
Background
Evidence-based practice (EBP) establishes a rigorous approach to gathering and summarising the best available evidence within a specific field or research purpose [1,2,3]. This paradigm has significantly changed the discourses and practices in various fields such as biomedical sciences, education, medicine, psychology, and public policy [3,4,5,6,7].
Evidence-based medicine (EBM) developed these principles to identify and evaluate medical information and provide structured summaries of the available evidence to inform decision in health care and improve the diagnosis and treatment of patients [1, 3, 8]. Systematic reviews (SR) are evidence synthesis studies that follow a structured method and are considered the most reliable source of evidence in the hierarchy of levels of evidence [9,10,11].
A SR aims to select, identify, critically appraise, and synthesise the best available evidence within pre-specified eligibility criteria to answer a clearly defined research question [9, 12-14]. This practice allows the consolidation of large amounts of findings from publications and the identification of potential evidence gaps in a specific field.
Without SR, decision-making processes are vulnerable to bias and would be often only based on a subset of studies that may not be representative of the knowledge base of the field. In addition, information overload due to increasing number of scientific publications, publication bias and heterogeneity of reporting, are challenges faced during decision-making process.
These raise the risk of obtaining biased results and flawed conclusions, and accurate evidence synthesis are key in many fields to informing the decision-making process. Promoting, enhancing, and facilitating the production of SR is therefore vital in the use of the best available evidence to inform healthcare decision-making processes [15,16,17].
The number of published systematic reviews has increased exponentially in recent years [18, 19]. However, conducting a SR is still a complex, challenging and time-consuming process [20, 21], and it requires a multidisciplinary team with at least one experienced reviewer [22]. The use of computational tools to assist and facilitate various stages of conducting a SR has always been relevant and the development of new tools has also seen a progressive increase [23,24,25].
Currently many tools are available [23,24,25,26], some of them providing support during some stages of the SR process and others supporting the entire workflow [27,28,29,30,31,32,33]. The types of software used can vary; including algorithms, packages (collections of functions or algorithms), libraries (collections of packages), desktop apps (programs that are executable from the desktop), and they may range from being locally run from a device to web-based applications (software accessible and executable through a web browser) that are hosted on a webserver.
As the WHO Classification on Tumours Programme (WCT) [34, 35] we wish to promote evidence-based practice in pathology. We need to review a very large amount of scientific literature to classify each of the 3,000 tumour types in the classification, ideally applying structured evidence synthesis methods by conducting SR. To produce so many SR with limited human resources there is a need for computational assistance. The WCT and EBP in general would benefit considerably from computational assistance to perform SR [3, 36] but tools that adapt well to the particularities of the fields of pathology and cancer diagnosis are not available.
The number of software tools and workflows to support the performance of systematic reviews, systematic maps, and meta-analyses is growing rapidly [29, 37,38,39]. Use of natural language processing (NLP) and machine learning (ML) algorithms to reduce time and workload in the SR process is becoming increasingly popular [29, 40, 41]. However, despite significant progress, integration of high-quality methodological approaches with user-friendly applications is rare. Well adapted open-source software is also rare, and integration among the different software tools is poor.
A vast number of free and fee-based tools exist, but there is a lack of validation and consensus when it comes to identifying which tool best fits specific needs. This limits the utility of computational tools, being especially difficult to find solutions to assist specific steps of the SR.
At present day some of the computational tools (e,g., web-applications, algorithms, executables, etc.) assisting the SR process are shown in Fig. 1, they can be found in online catalogues/repositories like the SR toolbox [42]. Around 160 tools assist the reviewer in either one specific step (during record search [43], screening [39, 44, 45], data extraction [45], risk of bias assessment/ critical appraisal, etc.), or guide the user through several steps or the whole SR process [46,47,48].
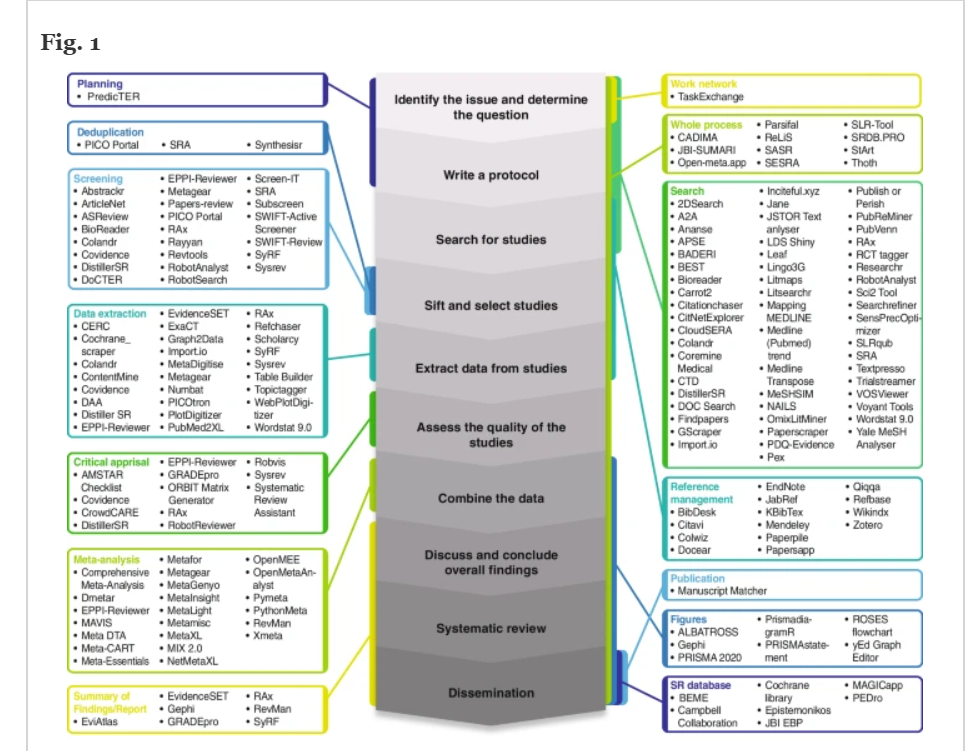
Software tools assisting the Systematic Review process. The central figure represents from the early to the late stages of the systematic review process described by the Cochrane Foundation (Higgins JPT et al., Cochrane Handbook for Systematic Reviews of Interventions version 6.3, Cochrane, 2022). The obtained tools were grouped into blocks depending on the covered SR step (Planning: Process of planning and writing the protocol for a SR; Deduplication: Process of removing duplicated records and articles retrieved by the search in a SR; Screening: Process of screening records and articles retrieved by the search in a SR; Data Extraction: Process of data extraction in the SR included studies; Critical appraisal and/or Bias assessment: Evaluation of the methodological quality and/or risk of bias in a SR included studies; Meta-analysis: Process of pooling findings of included studies, using statistical methods; Summary of findings/Report: Process of summarizing and reporting of findings; Work network: Process of networking; Whole process: whole systematic review process including all steps; Search: process of elaboration of search strategy, running the search and/or obtaining records retrieved by the search; Reference Management: process of screening and selection of records, as well reporting and scientific writing allowing management of large numbers of reference records and in text citations; Figures: Visualisation of data; SR Databases: Registration, collection and dissemination of SRs; Publication: Process of publishing the results).
Especially promising are ML techniques [49,50,51] for the automation of systematic reviews steps [41, 46, 52]. Within the artificial intelligence (AI) discipline, ML methods are considered the most promising techniques for working with unstructured data. These methods, usually combined with NLP technologies are used for text classification and data extraction, result in effectively assisting the article screening process during the performance of SR [29, 53, 54].
Machine learning is a multidisciplinary field that consists of the development of computer algorithms that can “learn” how to perform a specific task [51]. By using mathematics and statistics, the algorithms are trained to make classifications or predictions based on a provided set of training data, driving decision-making within specific applications. Unlike conventional algorithms, ML systems pretend to imitate human learning behaviour and can improve their performance without being directly re-programmed [54, 55].
So far ML algorithms are primarily employed to assist the article screening during the systematic review process. This process of screening publication records implies categorising them into groups (i.e., included or excluded), considering the research question and predefined eligibility criteria. Article selection is usually performed by two independent human reviewers, revising first title and abstract of the retrieved records, and later full text of the article.
The first step compromising the revision of title and abstract of a bibliometric record, is a task for which ML algorithms can be employed. These algorithms can be trained to develop the ability to categorise, using so called “training data sets” of records screened by human reviewers. This application of ML could be used to facilitate updating systematic reviews, since the categorisation from the original review can be used to train the algorithm for the screening of recently published records.
These algorithms are trained according to the computer–human interaction where the availability of a training data set and the purpose of the classification strategy are the key points [41, 49, 51, 55]. They can be broadly classified as supervised learning (trained on labelled data), unsupervised learning (trained without labelled data) and semi-supervised learning (trained by a small, labelled dataset and a large unlabelled data set) algorithms [53].
As mentioned above, these algorithms/software are more and more used for article screening in systematic reviews [53, 55, 56], with some examples being the programs Abstrack® [39], ASReview® [56], Colandr® [33], EPPI-Reviewer® [57] and Rayyan® [33], all easily accessible online. Other steps of the SR process such as data extraction [54, 58] or risk of bias assessment [59] have been also been exploring whether ML tools can facilitate the work. As an example, the software RobotReviewer® is able to assign low, high or unclear risk of bias to randomized control trials (RCTs) [59]. Additionally, the development of automatic data extraction tools is being investigated (for instance DistillerSR® [41, 46]), and important efforts are underway to explore whether ML tools can be used efficiently in combination with each other.
Most steps in the SR process can potentially benefit from automation [60], but they often require more sophisticated computational methods than those provided by ML [44]. However, developing automatic screening tools based on combined ML techniques seems feasible; plenty of research and developments have been done in this field in recent years [26, 39, 41, 46, 52]. Considering these advances, the rapid evolution of the area, and the difficulties in identifying the best suited tool for each task and field, we aimed with this project to systematically map available ML tools that assist the SR process [61]. No other mapping review on this topic has been published, and our findings will identify existing tools, detect potential development gaps, and help to guide future research towards the most promising areas.
Methods
See the original publication (this is an excerpt version)
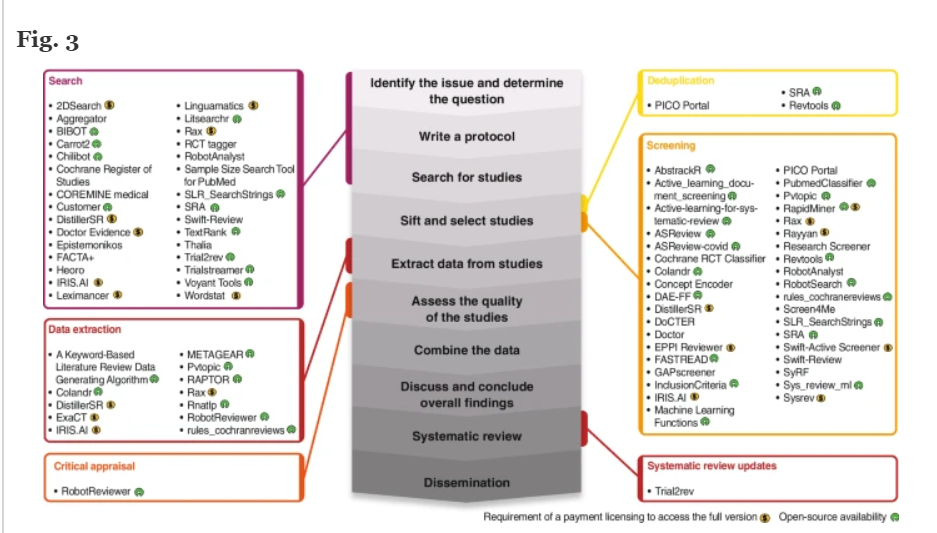
Machine learning tools that assist the Systematic Review process. The central figure represents from the early to the late stages of the systematic review process described by the Cochrane Foundation (Higgins JPT et al., Cochrane Handbook for Systematic Reviews of Interventions version 6.3, Cochrane, 2022). The obtained ML tools were grouped into blocks depending on the covered SR step. Next to the tool names, the yellow symbol means the requirement of a payment licencing to access to the full version of the tool and the green symbol open-source availability. SR = Systematic Review, ML = Machine learning.
Discussion
SR and meta-analyses are recognized as the highest level of evidence [3, 9, 11, 13, 17], and the growing number of available tools to assist during the performance of SR probably reflects an increasing recognition of the utility of this type of studies (see Fig. 1). It probably also reflects an increasing appreciation of the potential value of computational methods to simplify the performance of such highly structured reviews of the scientific literature, and also to improve their reliability and reproducibility. Recent years have seen the development of many ML tools that aim to reduce the immense human resources and time effort required by a multi-disciplinary team to develop such a review [29, 38, 52, 56]. One of the most assisted steps in the whole review process is the article screening, where these tools assist the reviewer by suggesting, classifying, or selecting records, and can either help or even replace the reviewer during certain parts of the process [28, 52, 71]. However, the current ML algorithms require evaluation and training using a pre-selected and labelled set of records, and their performance varies greatly depending on this previous step of training [41, 71, 72]. These requirements have hampered extended use of such tools by systematic reviewers for a long time and constitute an important barrier for their use in in topics with no representative training data sets to train the algorithms, as is often the case in the field of pathology. Also, when reviewing the retrieved tools more closely, it is obvious that most are not adapted to be used by users with no background in informatics or programming skills, who would require a tool with a user-friendly interface. Despite recent advances, increasing numbers of developments and new computational solutions to assist during the SR process, it remains a challenge for a reviewer to select the best suited software for each SR project. The results of this mapping review provide an overview of the currently available ML tools to assist during the performance of a SR and will help future reviewers and researchers to identify the right tool for each project and facilitate the development of new evidence synthesis methodologies (see Fig. 3).
It is evident that the ML tools identified by this review have been created with different aims by a great variety of developers, ranging from individuals and small research groups to large organisations dedicated to evidence-based medicine and systematic reviewing at a large scale [31, 37, 44, 56, 57]. These efforts have shown widely variable success so far and our final tool map shows that only a few tools are suitable for use by reviewers without programming backgrounds. Nevertheless the high proportion of free (70%) and open-source (49%) tools we have detected in this mapping review may indicate efforts by the SR community to overcome these limitations and produce tools to facilitate systematic review production for all types of users. We believe that there are signs of a growing movement of developers in the field that will probably continue to promote the progress of the automation of SR steps. It is crucial that such emerging collaborations continue to be facilitated in the future and open sharing of data as well as methods being promoted [23, 25, 26, 29]. Interestingly, amongst the free tools about 68% are open-source, showing once more that the two concepts of open-source and free-of-charge are similar, but describe views based on fundamentally different values: open-source is a methodology used to facilitate the development of software in a given field/task, while free software is a social movement aiming to provide equity in access. We identified also 14 (22%) ML tools that require the payment for a licence, and as expected, 10 (72%) are not openly accessible. This may point to an interest of private developers in these types of tools and their potential commercial value [57, 73, 74]. The access to such privately developed ML tools will be limited to the organisations or individuals that can afford their fees and will therefore not be an option for all reviewers. However, some of the payment-based tools might provide free access or fee reduction purchase depending on the review purpose and/or the team conditions (e,g., collaborating memberships, shared interests), as applying substantial discounts to lower middle-income country (LMIC) users and other similar situations.
Most of the identified tools (98%) were updated or released during the last 5 years, and 48% of all retrieved ML tools during the last year, which proves an increasing interest in ML software development in the field and probably indicates a marked demand for such tools. Not surprisingly, ML tools requiring payment for a license were far more frequently updated during the last year (86%) than freely accessible tools (30%), showing the advantage of the licenced approach for the rapid development of ML tools. However, most free tools (97%) have also been released or updated during the last 5 years, suggesting that this approach can also be efficient and produce updated products without relying on commercial strategies. Some not-for-profit research institutions appear to be highly interested in the development and promotion of SR automatization tools that are made freely available, which may in part be compensating for the funding disadvantage [26, 75].
Our findings show a major interest of developers in computational methods to assist the early stages of the SR process specifically during the screening of articles. It is in this step where automation seems to have greater potential for success, with 55% of the tools assisting in this step and being the most promising of ML solutions. The other two SR steps with promising developments are literature searching and data extraction, with 47% and 17% of the tools respectively. This seems to point towards an existing interest in the improvement of those stages using ML approaches, but probably less success in the development. Within the other SR stages, a reduced number of tools was identified, describing a minor interest or lack of potential for ML solutions for these SR stages.
It is understandable that web-applications are the biggest group of retrieved ML tools (62% of all tools, being 59% of them freely available and 26% open-source). This type of software generally permits easy access directly from a web browser and a user-friendly interface that doesn’t require any advanced knowledge of the software or programming background for a successful use. Utility and acceptability are likely to be high for these types of tools due to intuitive interfaces and potential to adapt to different reviewer profiles, but we have not been able to assess this in our review due to a lack of reporting of such features. However, web-based applications require extensive resources and a host (be it an institution, group, or enterprise) to provide web server maintenance, technical support, and to warrant a proper implementation of the tool. These resources are not always available for developers and it this is likely the reason for the large number of libraries/packages and algorithms we retrieved. These constitute the second largest block comprising 25% of all retrieved ML tools and are fully developed, but inactive software tools that require further steps for their implementation. These tools comprise one or more algorithms and require knowledge in informatics and programming skills for their application, which significantly reduces the tools’ usability. Hence not a solution for all reviewers, but still a valuable tool that permits customization and can be tailored to the specific needs of a project with the necessary skills. Interestingly, ML packages/libraries and algorithms showed the highest proportion of free (100% both) and open-source (100% both) tools compared to the other types of software described. Desktop applications were rather rare with 8 mapped ML tools, even though this type of tool allows the user to locally execute the software from a computer after installation. This process and laborious implementation steps may limit their usability, but no programming skills are required, and this may turn them into one of the most promising solutions. This may be even more so the case if an easy installation and compatibility with common operating software can be assured. However, our findings suggest that further developments are needed and that at this stage it results still difficult to assess which type of software is best suited for single review projects and reviewer profiles. Factors such as research topic, composition and expertise of the review team, available resources, and technical skills, still need to be considered and are the challenges for future development.
Only a few tools obtained more than 5 citations either in scientific publications or software repositories. Not surprisingly, among those were some of the best-known and most used tools as Abstrackr® [39], EPPI-Reviewer® [57], Rayyan® [33], and RobotReviewer® [31] (see Table 1).However, the majority of identified tools (83%) were cited less than 5 times, suggesting that despite the increasing development of software to assist the SR process, new tools will have to compete with a few dominant well-known tools. Efforts to improve the diffusion of the newly developed tools is therefore key, together with an improvement of currently applied methodology.
We believe that collaboration to improve already available ML tools may yield well adapted software that can provide a wide range of functionalities needed for systematic reviews, as shown by the already existing variety of ML tools and the recent acceleration in the launch of new and updated version. There are projects such as Metaverse [76], where developers collaborate to collect, integrate, and expand available functions, following open-source principles and making the tools freely accessible to the evidence synthesis community. Other projects as SR-Accelerator [28], integrate several tools in a suite to assist in more than one step of the SR procedure, aiming to produce software that guides and assists the reviewer during the whole process. Additionally software repositories or toolboxes such as the SR toolbox [42, 70] exist to promote and share already available tools that assist the SR process. Databases or repositories with specific training sets are also a resource that helps the community of developers perform collaborative work, providing the necessary platforms for the sharing of data, information, and expertise.
Following this successful development, more efforts should be undertaken to facilitate communication and knowledge exchange among developers and users, so that usability and functionality of already existing tools can be improved and adapted to the needs of different systematic review projects. Training in SR automation for reviewers, provision of basic programming skills, and plain language explanations on how to adapt tools to specific needs, may also speed up the development of better ML tools, or even promote the creation of new ones.
Our systematic mapping review holds potential for bias inherent to the limitations of its methodology. However being a mapping exercise, risk of bias as that of selective reporting [77], could be minimized by applying few exclusion criteria and reporting on all identified tools for which we could retrieve sufficient information. This also avoided a potential selection bias, and by following a previously defined and registered protocol we assured the reliability and reproducibility of our work. The lack of advanced search functionalities in the search engines of software repositories did not permit sophisticated search strategies and ML tool registries might not have been detected. Nevertheless, the iterative search process in these repositories combined with the sensitive search strategy applied in the bibliographic databases strengthen the completeness of our findings, and the high number of records screened makes this mapping review highly reliable. However, due to fast evolution of the targeted field, new potential tools have been developed since the performance of this project, being the Elicit tool [78] an example of a tool that the developed search strategy haven’t considered. Despite the fact that the applied methodology does not provide a synthesis of the findings or a critical appraisal of the methodological quality of the retrieved publications, our mapping exercise has value and pertinence. Our description of available tools, visually summarized in two comprehensive infographics provide a decision support tool for reviewers, researchers and other decision-makers conducting and funding evidence synthesis projects. This mapping review covers the breadth of science in ML tools and is needed to assist related questions. The unique overview that it provides will inform future reviewers, developers, and research in the field.
Conclusion
Systematic reviews (SR) are considered the most reliable source in the hierarchy of the evidence levels, they permit the combination of large amounts of findings from scientific publications and the identification of potential evidence gaps in a field. Without SR, decision-making processes are exposed to bias and flawed conclusions.
The development of computational tools to assist the systematic review process is rapidly expanding, this reflects an increasing interest on the production of this type of studies. Our review provides an overview of available software to assist the performance of SR according to SR steps, and a complete map of ML tools, showing that ML algorithms represent one of the most investigated methods for the assistance of SR. The most promising approaches focus on the automation or semi-automation of parts of the process and include a high number of easy to use and easy to access web-based applications that permit the use of ML software for SR and other kind of evidence synthesis reviews.
Our results have uncovered the current state of open-source development and how it could support a call for the formation of collaborative working groups in this field. Promoting and facilitating the production of SR by using computational assistance is therefore crucial in the use of the best available evidence to inform healthcare or any decision-making processes.
Availability of data and materials
All data generated or analysed during this study are included in the published article and its additional files.
References
See the original publication (this is an excerpt version)
International Agency for Research on Cancer (IARC/WHO), Evidence Synthesis and Classification Branch, Lyon, France
Ramon Cierco Jimenez, Ian A Cree & Blanca Iciar Indave Ruiz
Laboratori de Medicina Computacional, Unitat de Bioestadística, Facultat de Medicina, Universitat Autònoma de Barcelona, Bellaterra, Spain
Ramon Cierco Jimenez & Angel Gonzalez
International Agency for Research on Cancer (IARC/WHO), Services to Science and Research Branch, Lyon, France
Teresa Lee
Servicio de Medicina Preventiva, Hospital Universitario 12 de Octubre, Madrid, Spain
Nicolás Rosillo
International Agency for Research on Cancer (IARC/WHO), Nutrition and Metabolism Branch, Lyon, France
Reynalda Cordova
Department of Nutritional Sciences, University of Vienna, Vienna, Austria
Reynalda Cordova







