health transformation
institute
health transformation, health strategy
and digital health
Joaquim Cardoso MSc
Chief Researcher for — Health Transformation Research
Chief Editor for — Health Transformation Portal
Chief Senior Advisor for — Health Transformation Advisory
Chief Strategy Officer (CSO) for — Health Transformation Consulting
May 21, 2023
The development and proliferation of large language models (LLMs) like ChatGPT and Bard have raised concerns among scientists and researchers due to the lack of understanding about how these AI chatbots work.
Unlike traditional computer programs, LLMs, which are powered by neural networks, program and reprogram themselves in ways that are not comprehensible to humans.
This “inscrutable” nature of LLMs has led to fears that their continued advancement could have unintended and potentially catastrophic consequences.
Scientists worry that bad actors or defense agencies could misuse LLMs, and some believe that as AI systems become more intelligent, they may see humans as barriers to achieving their goals.
The lack of understanding of LLMs has prompted calls for a pause in their development.
Over 1,000 business leaders and scientists, including prominent figures like Yoshua Bengio, Steve Wozniak, and Elon Musk, signed an open letter highlighting the need for a better understanding of AI systems.
The concerns are amplified by figures like Geoffrey Hinton, known as the “godfather of AI,” who recently expressed worries about the evolution of AI and its potential impact on humanity.

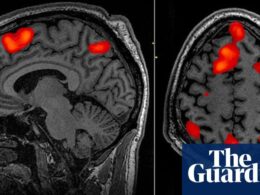
Interpreting the inner workings of LLMs is challenging due to their complex neural network architecture and the vast number of interconnected neurons involved.
Mechanistic interpretability, which involves reverse engineering the neural network to understand its processes, is one approach being explored.
However, studying LLMs at this level of detail is difficult and time-consuming, and there is ongoing debate within the AI community about the necessity and feasibility of achieving complete interpretability.
Interpretability research is crucial for establishing safety measures around LLMs, such as identifying and correcting unsafe outputs or establishing guidelines for acceptable behavior.
However, current methods have limitations, and researchers are working to find ways to steer LLMs without compromising their creative capabilities.
The lack of standardized benchmarks for measuring interpretability further complicates the research landscape.
Beyond immediate safety concerns, the potential alignment problem arises as LLMs continue to advance and surpass human intelligence.
Without a thorough understanding of their underlying mechanisms, ensuring that AI systems remain aligned with human interests becomes increasingly challenging.
Experts like Eliezer Yudkowsky and Geoffrey Hinton express doubts about humans’ ability to manage AI alignment effectively and emphasize that achieving mechanistic interpretability alone is not a guaranteed solution.
The lack of understanding regarding the inner workings of AI chatbots poses significant challenges and risks.
Researchers are grappling with the complexities of interpreting LLMs and establishing safety measures.
The AI community needs to invest in interpretability research and work towards standardized benchmarks while addressing the broader issue of AI alignment to ensure the responsible development and deployment of AI systems.
Adapted from “The frightening truth about AI chatbots: Nobody knows exactly how they work”, published by “The Fast Company”, and authored by “Mark Sullivan”