the health strategy . institute
multidisciplinary institute for
digital health + health strategy
Joaquim Cardoso MSc
Chief Research and Editor;
Chief Strategy Officer (CSO), and
Senior Advisor for Boards and C-Level
June 20, 2023
Key message(s)
The success of generative AI startups heavily relies on access to the right data.
While significant funding is pouring into this sector, the scarcity of data inhibits their ability to build powerful AI models.
- Startups face obstacles related to data ownership, client trust, cybersecurity, and negotiating mutually beneficial agreements.
- Overcoming these challenges will be critical for their long-term viability and competitiveness in the market.

ONE PAGE SUMMARY
Generative AI startups are attracting substantial funding in the billions of dollars, but their success is being hindered by a lack of access to the right data.
While the application of artificial intelligence shows great promise, the availability of high-quality data is crucial for building powerful AI models.
In today’s landscape, where model building has become somewhat commoditized, the real value lies in the data itself.
Startups face significant challenges in obtaining the necessary data, as big companies are hesitant to share their proprietary data with them.
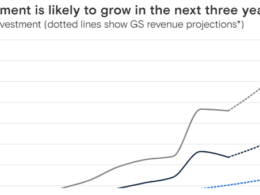
According to PitchBook, venture funding in generative AI startups has grown from $4.8 billion in 2022 to $12.7 billion in the first five months of 2023.
However, these companies encounter difficulties when trying to access specific training datasets, particularly in industries such as finance and healthcare.
Some startups are seeking partnerships with data-rich enterprises to overcome this hurdle.
However, concerns arise regarding data ownership and access rights, making it challenging to reach mutually beneficial agreements.
One potential workaround for startups is to train separate models for each client using only that client’s data.
This approach requires educating and convincing clients about the benefits and security of this strategy.
Ensuring strong cybersecurity measures and data protection is also crucial for gaining the trust of enterprise clients.
Large tech incumbents hold an advantage over startups in generative AI applications because they already have the trust of established customers.
The reluctance of enterprises to share data extends to publicly available data as well.
Startups, such as Veesual, which generates images of people trying on clothes, initially relied on public images for training.
However, they struggled to convince large retailers to share their data to enhance the model.
Some retailers demanded significant payouts or equity stakes in exchange for access to their data, leading to unsuccessful negotiations.
Startups also face challenges when trying to incorporate customer feedback to improve accuracy, as this feedback must be separated from sensitive and confidential data.
The pressure to acquire data quickly is mounting, with startups competing against each other within specific niches.
The pursuit of proprietary data has turned into an arms race, with startups racing to secure exclusive access.
However, early-stage startups face challenges related to brand recognition and social proof, making it difficult to compete effectively.
This is an Executive Summary of the article “”AI Startups Have Tons of Cash, but Not Enough Data. That’s a Problem”, authored by “Isabelle Bousquette”, and published on the “Wall Street Journal”, on June 15, 2023