




Sepsis Watch helps flag a potentially deadly reaction to infection
The Verge
by Nicole Wetsman
Mar 23, 2022
Illustrations by Grayson Blackmon
Site version edited by:
Joaquim Cardoso MSc.
Health Transformation Institute
Continuous transformation
for better health, care, costs, and universal health
July 2, 2022
Artificial intelligence algorithms are everywhere in healthcare.
They sort through patients’ data to predict who will develop medical conditions like heart disease or diabetes, they help doctors figure out which people in an emergency room are the sickest, and they screen medical images to find evidence of diseases. But even as AI algorithms become more important to medicine, they’re often invisible to people receiving care.
Artificial intelligence tools are complicated computer programs that suck in vast amounts of data, search for patterns or trajectories, and make a prediction or recommendation to help guide a decision.
Sometimes, the way algorithms process all of the information they’re taking in is a black box — inscrutable even to the people who designed the program. But even if a program isn’t a black box, the math can be so complex that it’s difficult for anyone who isn’t a data scientist to understand exactly what’s going on inside of it.
Patients don’t need to understand these algorithms at a data-scientist level, but it’s still useful for people to have a general idea of how AI-based healthcare tools work, …
… says Suresh Balu, program director at the Duke Institute for Health Innovation. That way, they can understand their limitations and ask questions about how they’re being used.
Some patients can get a little jumpy when they hear algorithms are being used in their care, says Mark Sendak, a data scientist at the Duke Institute for Health Innovation. “People get really scared and nervous, and feel threatened by the algorithms,” he says.
Those patients can be nervous about how hospitals are using their data or concerned that their medical care is being directed by computers instead of their doctors.
Understanding how algorithms work — and don’t work — may help alleviate those concerns. Right now, healthcare algorithms have very narrow uses: a computer program isn’t going to make major medical decisions, but it might help a doctor decide whether a set of medical scans needs closer scrutiny.

To help demystify the AI tools used in medicine today, we’re going to break down the components of one specific algorithm and see how it works.
We picked an algorithm that flags patients in the early stages of sepsis — a life-threatening complication from an infection that results in widespread inflammation through the body.
It can be hard for doctors to identify sepsis because the signs are subtle, especially early on, so it’s a common target for artificial intelligence-based tools. This particular program also uses mathematical techniques, like neural networks, that are typical of medical algorithms.
The algorithm we’re looking at underpins a program called Sepsis Watch, which Sendak and Balu helped develop at Duke University.
Sepsis Watch went online in 2018 after around three years of development. Today, when someone is hospitalized at a Duke hospital, the program could be keeping an eye on them.
Here’s what it’d be doing.
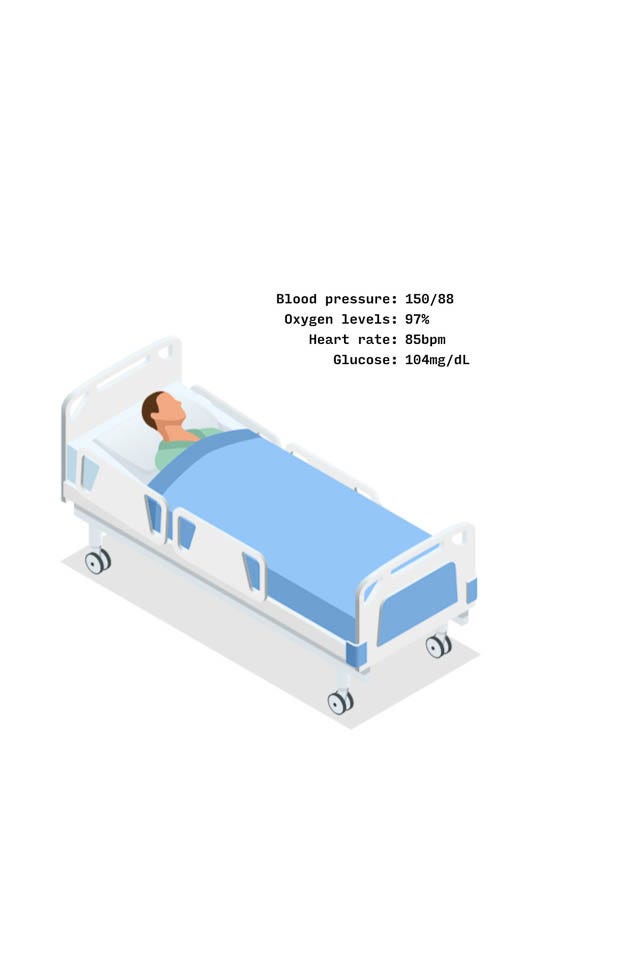
Many factors play into a person’s risk of developing sepsis, including age, immune-compromising health conditions, and length of hospital stay. Signs from all over the body can tell a doctor when it may be occurring, including things like blood pressure, heart rate, and body temperature.
In order to make a prediction, the Sepsis Watch program first needs consistent data about a patient.
Let’s take a hypothetical patient, Alex — a 58-year-old hospitalized with an infection. Some of Alex’s data is easy to capture and feed into the program, like their age, preexisting conditions (kidney disease) or previous medications (cholesterol medication) — which won’t change while they’re in the hospital bed.
But other metrics are more dynamic. Alex’s blood pressure can change through the course of the day. So could their oxygen levels, heart rate, or glucose levels. And not all of those things are measured at regular intervals.
The program, though, doesn’t care if it’s unreasonable to expect a blood test on Alex every hour — it needs the data regardless. So the first step it takes is to fill in the gaps on those inconsistent metrics.
It uses a method called a Gaussian process to do that.
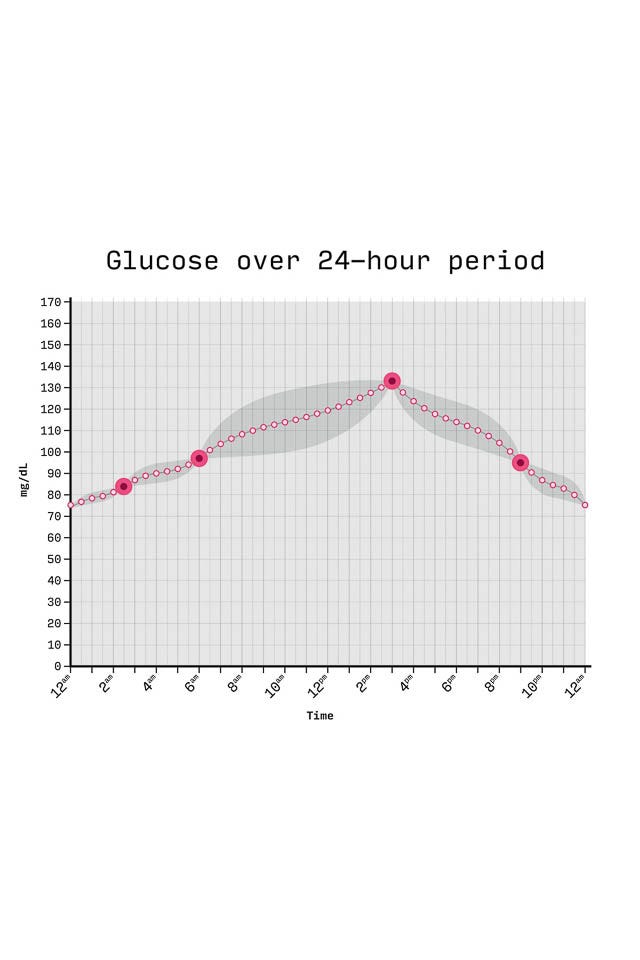
Say Alex only had their glucose levels measured at 2:30AM, 6AM, 3PM, and 9PM.
The mathematical tool uses information from those measurements, as well as information about Alex’s other vital signs, to fill in the gaps.
It figures out the best way to draw a line through all the existing data points, and adds in any missing numbers along that line. With a smooth line of evenly spaced data points in place, it can now see what Alex’s glucose level should have been at regular intervals throughout the day.
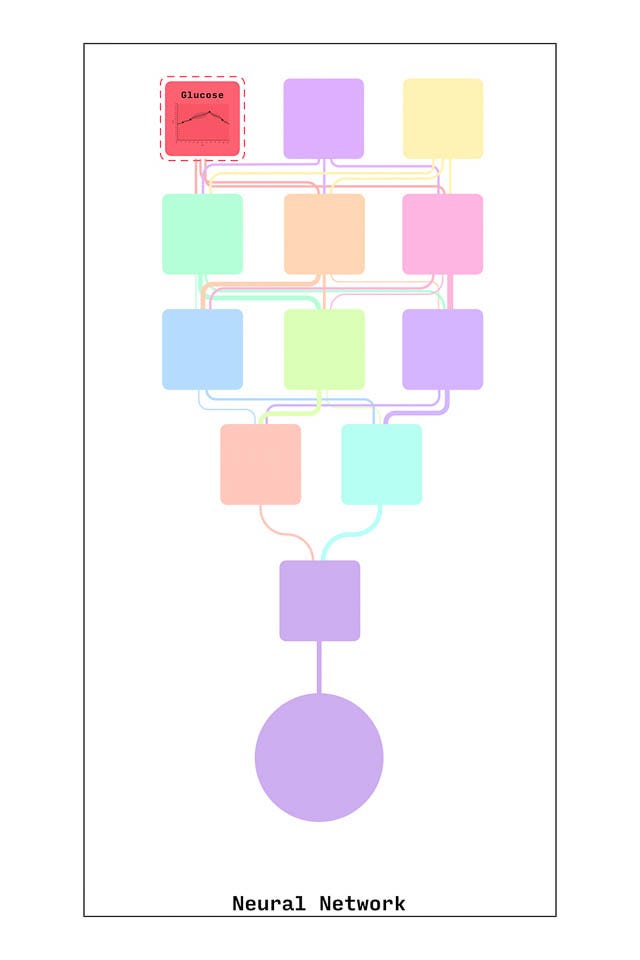
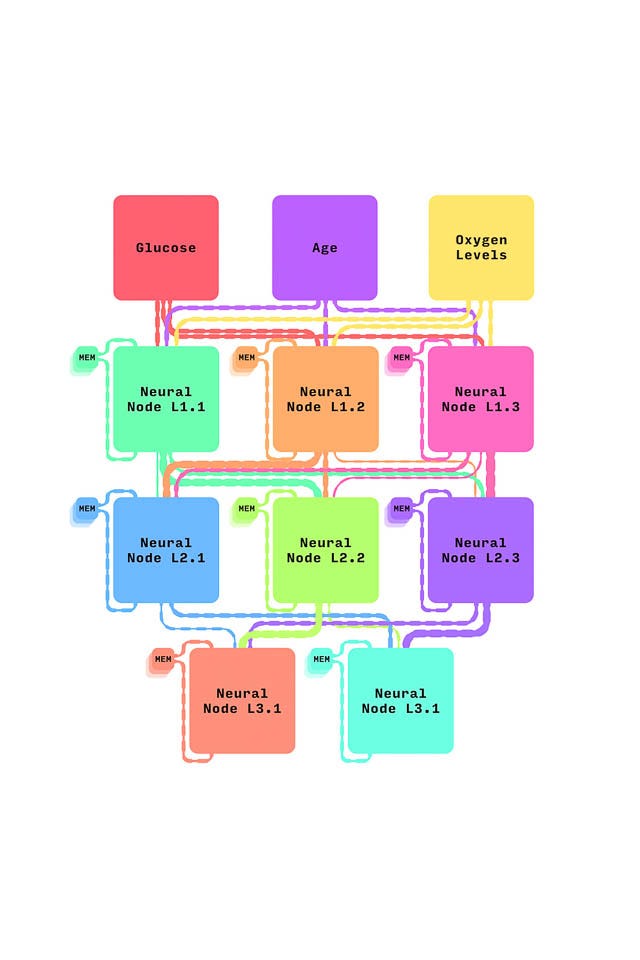
All that data can now be packaged, and fed into the neural network.
The neutral network underpinning Sepsis Watch is a complex series of algorithms that search for patterns in messy data. It’s made up of a series of “nodes” that each take in data, process it, and send it on to the next node before eventually spitting out an answer.
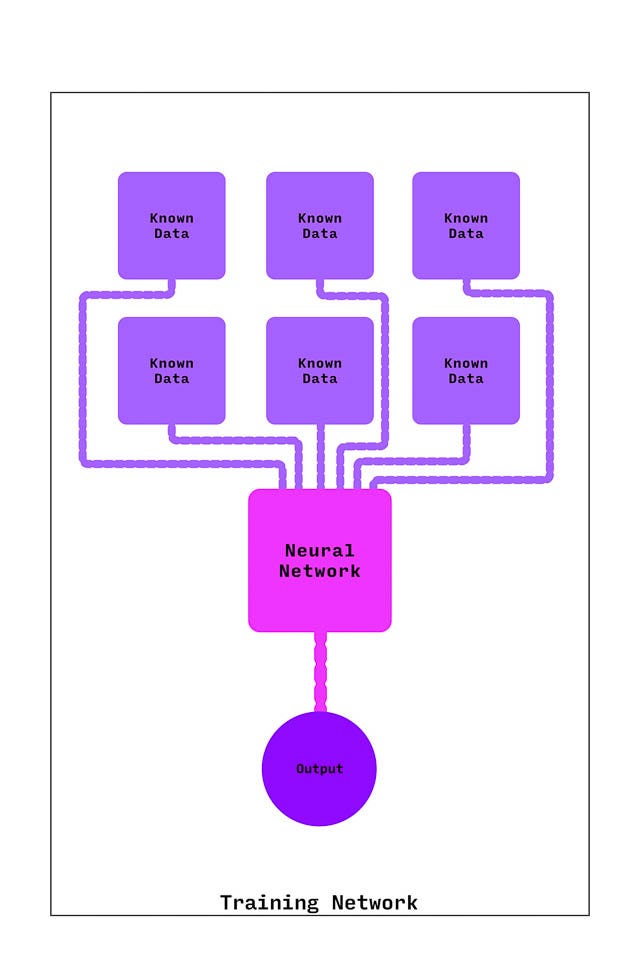
Before it was put into use on patients, the neural network got extensive training. It was fed hundreds of examples of data from patients who had sepsis and patients who did not.
Each time it received new data, the network refined the way it worked with that data until it could reliably pick out what patterns and combinations of data meant someone was likely to have sepsis.
After that training, it’s ready to get real-time information from Alex. (These are just a few examples of the dozens of types of information it receives).
Data gets fed into nodes of the neural network, which give different weights to the information.
Each node gets additional information from a memory bank, where the neural network stores all the information it learned from previous times the program ran on Alex.
For an analysis at 10PM, then, each node would also pull on the memory of the decisions it made at 9PM and 8PM for Alex.
Multiple nodes make up each layer of the neural network
And that all goes to the next layer, with its own nodes and memory banks
And then to the next layer
After the data is processed by that complex sequence of algorithms, the neural network spits out a score between 0 and 1 — a probability that Alex has sepsis at that particular moment in time. The closer the score is to 1, the more likely it is that Alex has sepsis.
This is a simplification of an incredibly complex mathematical program that, in reality, is made up of dozens of nodes and built from detailed equations. But at the end of the day, it’s still giving doctors and nurses one simple number that can help them care for patients.
Asking doctors and nurses to incorporate the Sepsis Watch alerts into their routines — and asking them to make choices and decisions based on what it told them — wasn’t a seamless process. The teams using the program had to figure out the best ways to communicate with each other about the information it gave them and how to adjust the way they engaged with patients and each other.
At all stages, human choices played and continue to play a big role in how sepsis is managed. People choose what type of mathematical tools scaffold the program and what type of data trains it. People also have to decide on thresholds for what counts as a low, medium, or high risk of sepsis based on the output of the program.
Doctors and nurses are still the ones making treatment decisions after a Sepsis Watch alert comes in. They call in prescriptions, monitor patients to see how they respond, and decide if and when they should keep using an algorithm to keep an eye on them.
“At that level,” Balu says, “you’re relying on clinical judgment and clinical experience.”
But so far, the effort to integrate Sepsis Watch seems to have been worth it: deaths from sepsis seem to be down at the Duke hospitals, and Duke is working on a more rigorous evaluation of how well the program contributed to that decline. That could make people more comfortable with the technology, too.
Algorithms don’t fix problems in medicine. They’re human tools — they can reflect and exacerbate problems and bake in bias if the people developing the tools aren’t careful. But for better or worse, they’re going to be more and more ubiquitous. That’s why it’s so important to examine them carefully. “It’s important to have rigorous evaluations and validations,” Sendak says. “And to have transparency — about the data, about the performance, and about strengths and weaknesses.”
Originally published at https://www.theverge.com on March 23, 2022.
NAMES MENTIONED
Suresh Balu, program director at the Duke Institute for Health Innovation.
Mark Sendak, a data scientist at the Duke Institute for Health Innovation.







