




BCG — Boston Consulting Group
BCG Gamma
Authors: Yegor Smurnyy, Mathias Blom & Satty Chandrashekhar
January 31, 2021
As the healthcare data landscape becomes ever more complex, new standards are being developed that will accelerate data exchange and improve accessibility.
Despite widespread availability of technology and abundant healthcare data, the AI-driven healthcare industry revolution has yet to fully arrive.
One particular challenge has been the industry’s inability to successfully validate and scale algorithms beyond those proofs of concept reported in academic papers. This shortcoming has contributed to the relative scarcity of AI applications at the frontlines of clinical practice.
This challenge is due, in large part, to a fragmented data landscape and a lack of the necessary data infrastructure.
Without these, healthcare organizations are unable to collect the data they need to adapt algorithms to local conditions, and then to interrogate the data for bias. Attention to bias is particularly important for ensuing reliable algorithmic performance across patient groups with different characteristics. Looking ahead, reliability will become increasingly important as organizations scale applications to meet the needs of new geographies, emerging healthcare systems, and other broad changes to the market.
Even in cases where high-quality data are available, disparate definitions of key data elements across healthcare systems and settings make validation difficult.
Shared and transparent definitions have therefore become a pressing need across the industry.
Boston Consulting Group has a strong legacy in value-based healthcare and health outcomes measurement, while BCG GAMMA retains a leading position in the implementation of AI systems at scale across industries.
Coming from these backgrounds, we the authors have had the opportunity to support the development of an emerging health-outcomes data standard produced by the International Consortium for Health Outcomes Measurement (ICHOM).
Our goal in this article is
- to provide an overview of key concepts and technologies in the healthcare information standards and interoperability space.
- We will also share lessons learned from our numerous collaborations with thought leaders in the field.
(For a closer account of the method deployed with ICHOM, please refer to the recent publication in the open access journal “ Frontiers of Digital Health.”)
Index:
- A Primer on Standards
- The Three Faces of Interoperability
- Benefits Differ Per Stakeholder
- Early Standards and the Creation of HL7 v2
- The Standards Evolution Continues
- FHIR: A New Standard Arises
- Practical Ways to Achieve Interoperability
- Emerging Themes in Interoperability Research
- Will FHIR Become the Future of Interoperability?
A Primer on Standards
First, a definition: Interoperability in healthcare informatics refers to the shared sets of standards and formats that enable data exchange across systems.
Such exchanges are key to unlocking the data-driven insights that hold promise to transform the healthcare industry.
The healthcare industry lags behind many other industries in this respect, due in part to often-siloed organizational structures that give rise to compartmentalized data and information systems.
This characteristic, combined with the inherent sensitivity of health records, has led many industry participants to adopt very conservative views of data-exchange technology.
To an outside observer, the healthcare industry might appear confusing with its multiple, conflicting standards and its fragmented tech ecosystem.
Despite the fact that the industry features a number of standards and major standards-issuing organizations, their adoption is frequently varied and differing approaches are often taken by different industry participants.
These variations have thus far prevented the industry from achieving its long-sought-after goal of full data interoperability.
The Three Faces of Interoperability
Depending on the context, a specific aspect of interoperability may be particularly important.
- In some situations, the interoperability in data transmission with respect to end-user privacy controls or levels of service may be of primary concern. In others, it may be the representation of the data in a scaled data asset.
- In still others, the critical aspect may be the meaning of individual data elements.
All aspects of interoperability can typically be divided into either technical, structural or semantic categories:
- Technical interoperability refers to the shared set of exchange protocols, APIs, and other technical functionalities that enable the reception and transmission of data across applications. At this level, the primary concern is the means of data exchange in a content-agnostic manner.
- Structural interoperability refers to data fields and metadata that enable the receiving application to understand the type of data being transmitted and received. A structurally interoperable application, for example, would recognize upon receipt that a collection of ICD-10 diagnosis codes transmitted from an EHR system to a quality registry are, in fact, ICD-10 diagnosis codes.
- Semantic interoperability relates to a shared understanding between applications or agents exchanging data of the meaning of individual data elements. For example, two systems would lack semantic interoperability if an application for health-outcomes benchmarking compared the survival rates of healthcare providers’ patients reported to have had “surgery complications” — without differentiating by the subtype of complication. The goal of a growing number of standards, medical terminologies, and ontologies is to ensure that the exchanging parties have a shared understanding of the semantic meaning of an individual concept, such as a particular diagnosis, procedure, or lab result. Once again, varying adoption of different standards and the lack of a common approach to interoperability impedes the industry and highlights the need for significant additional progress.
Structural interoperability has been impacted the most by developments in technology. Nevertheless, the three aspects are intertwined in practice: No system designer would attempt to achieve structural interoperability without at least some alignment on semantics.
Benefits Differ Per Stakeholder
While interoperability is hard to achieve, the industry has made significant progress, thanks to fairly strong stakeholder-specific incentives:
Providers:
Secure and efficient data exchange improves transparency,
- which can reduce redundant care (e.g. procedures, diagnostics etc.)
- and enable better coordination between care teams.
- Benefits include reduced waiting times for patients and idle time for staff.
This, in turn, can lead to improved patient outcomes, better patient experience, and lower costs.
Payers:
- For these stakeholders, increased transparency can help identify waste and opportunities for improvement among providers
- and become an important technical enabler of value-based reimbursement programs.
This is particularly important for government-run healthcare systems for whom incentives to change healthcare processes are better aligned with payer priorities.
EMR and other IT vendors:
Market leaders have incentives to promote proprietary APIs and limit the ease of exporting EMR data to external applications.
- Increasing regulatory pressures, however, can make IT vendors more supportive of data exchange standards.
We are already seeing significant vendor investment in and support of common standards such as HL7 FHIR.
Early Standards and the Creation of HL7 v2
The first widely successful approach to an interoperability standard for healthcare was based on X12, an ANSI-supported data exchange standard not specific to healthcare. The standard takes an approach in which a large file is divided into messages, each carrying a prefix that identifies what the message is (such as a “benefits eligibility inquiry”) along with the message body itself. It is worth noting that this 1970s-era format is still widely used in healthcare, especially in payer IT, and is part of Health Insurance Portability and Accountability Act (HIPAA) mandated data-exchange standards.
In the late 1980s, a group of US academics and government contractors formed a standards organization called “Health Level 7” or, simply “HL7,” to make multiple X12-inspired data exchange standards conform. (The “7” in HL7 refers to the 7th “Application” layer in the OSI telecommunication model.) The organization quickly developed HL7 v1 and v2, two iterations that extended the original ideas behind the X12 standard. According to these iterations, each message typically consists of one line that uses prefixes to identify the nature of the information, and line separators to organize the information within the line.
In our opinion, the HL7 v2 standard represented a significant breakthrough and solved several problems particularly well. First, its compact messages demanded few resources. It also handily covered the most common and important types of records such as demographics data. And with its roots in X12, an already widely used standard, it was assured quick industry adoption.
Given these attributes and the substantial investments in v2 implementations made by a large number of providers, it comes as no surprise that it HL7 v2 remains one of the most common interoperability standards.
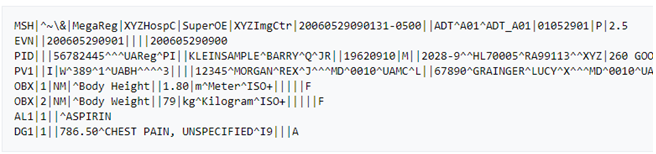
Example of HL7 v2 messages
The Standards Evolution Continues
As successful as HL7 v2 was, it was not long before its limitations became clear. First, HL7 v2 is known for being highly customizable, to the degree that many custom implementations do not achieve interoperability. As a result, HL7 has limited practical use for data exchange without significant additional coding. Second, HL7 v2 messages do not describe data context. In other words, it is not possible to tell exactly what a specific part of the message is without reading the specifications. Third, HL7 v2 messages have poor human readability. Finally, the information in HL7 v2 messages is not tied to a bigger clinical picture. As such, it is very difficult to reconstruct a full patient journey, care plan, or meaningful episode of care from HL7 v2 without bringing in knowledge from other sources or devising heuristic rules. The continued evolution of HL7 standards is intended to address these challenges.
HL7 v3, published in 2005, was the next iteration of the standard. Improvements over previous versions include:
- Reliance on XML: As the idea of a markup language that would be both human and machine-readable became increasingly attractive, XML became the natural choice to replace the mainframe-era, one-liner format.
- Introduction of CDA (Clinical Document Architecture) and a later iteration, the more restrictive consolidated CDA (C-CDA). Both of these formats were designed to replace common paper forms by combining data elements in way that made clinical sense. For example, Care Plan, Referral Note, and Transfer Note can all be represented as a C-CDA.
We would argue, however, that v3 of the standard was overly conservative. It did not, for example, depart from the concept of a document-centric health care record. Still anchored to the paper patient record convention, v3 did not provide a technology fit for a world in which healthcare records are becoming increasingly decentralized. Nor did it anticipate that a significant amount of information would be collected outside of formal encounters between patients and physicians, such as through patient-reported outcomes or wearable technology. Its document-based approach also means that individual units of information cannot be readily retrieved. If a medical diagnosis or a lab value is embedded in a more comprehensive document, there is no way of retrieving that particular unit of information without first serializing the entire document.
FHIR: A New Standard Arises
Ten to fifteen years ago, at about the same time HL7 v3 was proposed, Web and mobile apps reliant on REST or SOAP APIs were becoming increasingly popular. With the rise of the number of health IT apps in general and consumer-facing software in particular, many more developers also entered the field.
This dual influx created the need for a standard aligned with API design principles used elsewhere, and that was easy to learn and to extend. Fast Healthcare Interoperability Resources, or FHIR (pronounced “fire”) became this new standard and is now poised to replace both HL7 v2 and v3.
FHIR is finding a ready audience thanks to its emphasis on:
- The use of individual resources, such as Patient or Appointment, instead of a document, which leads to greater flexibility of the standard.
- The use of HTTP-based RESTful protocol, instead of messaging, that has become a more common approach to client-server applications.
- Flexibility in markup languages used to express resources, along with first-class support for XML, JSON, RDF.
Initially, FHIR did not define any authentication mechanism. That has changed with the introduction of SMART on FHIR, the technology layer that adds authentication and user-identity management capabilities using OAuth2 and OpenID.
Since its creation in 2011, FHIR has been rapidly gaining traction. This is taking place despite certain FHIR limitations such as lack of backward compatibility between non-normative FHIR versions, and the fact that a majority of FHIR resources are still in the process of development. For us and for many others in the field, rapid adoption of FHIR represents the promise of a unifying, commonly adopted, yet flexible standard for the frictionless exchange of patient data. We believe that FHIR will lead to improvements in outcomes and better utilization of resources, despite one of the main challenges to its wider adoption — that, as with HL7 v2, the high degree of flexibility and customization possible with FHIR may limit its interoperability across implementations.
Practical Ways to Achieve Interoperability
In our opinion, the landscape remains fragmented in terms of both the standards (HL7 v2 and v3, C-CDA, X12, FHIR) and the types of software (EMRs, billing, scheduling, lab information systems) used. Nevertheless, we identify four common approaches to integrating different systems:
1. Proprietary APIs: The developer makes calls to endpoints specific to a given EMR. This traditionally has been the most common option and, while it has the clear drawback of having to redo work for a new integration, it is the most straightforward approach and allows full leverage of EMR capabilities. All leading EMR vendors have developer programs and sandbox environments that allow testing, running code and sometimes, if desired, the ability to publish the app in an app store.
2. FHIR: The developer uses a version of the standard to fetch resources. Theoretically, using FHIR would guarantee easy portability between different EMRs. In practice, however, challenges may arise: Different versions of FHIR are not always compatible with each other. Furthermore, code must be built to extract the data to populate the FHIR response. While some hospitals may have invested in such code, others may not have, once again making the two systems incompatible. Nevertheless, FHIR APIs are featured prominently in all EMR software development toolkits and the industry seems to have doubled down on FHIR as its future standard.
3. Third-party integration engines: The complexity and fragmented nature of data exchange protocols has led to the creation of a specialized market for solutions that harmonize dozens of healthcare systems into one proprietary API. Some platforms offer “Swiss Army knife” capabilities and can integrate across a variety of data formats, while others are more specialized for a particular kind of data, such as billing or lab results. The market is dominated by several for-profit companies, but open-source projects such as Mirth Connect do exist.
4. Integrating at the storage level. The least conventional but still powerful approaches are to either query the storage layer directly, or to set up export from EMR tables to other parts of the data warehouse. Almost all EMRs are built on top of industry-standard relational or document-oriented DB engines and it is often possible to write queries against the tables representing healthcare data. The drawback to these approaches is that they are “hacky” — potentially hard to maintain and may lose much of the context present in structured HL7 messages.
Emerging Themes in Interoperability Research
HL7 standards, including FHIR, represent a traditional approach in which data is joined using a combination of non-unique and mutable data fields such as name or address.
This leads to multiple problems including, most importantly:
- Incomplete or ambiguous matching of patient records. (It has been reported that, in some cases, up to 50% of patient records cannot be matched when joining two sets.)
- The fact that some data that might otherwise need to be joined may contain sensitive and legally protected information.
While the interoperability problem is not fully solved, there are a number of promising new approaches.
- One includes the use of biometric data as the unique patient ID.
This approach leverages the fact that biometric data is immutable and easily collectable. In this approach, participating institutions would independently collect biometric data to accompany a patient record, and then use the biometrics as a key to join datasets, resulting in a nearly 100% match rate. To protect patient privacy, the raw data can be hashed or encrypted to create a dataset that would be of little practical use to would-be hackers or other malicious actors.
While this approach does hold promise, many aspects of it still need to be solved. For instance, more work needs to be done on the development of standards for data collection, storage, and protection. To gain traction, industry-wide consensus needs to be built in support of this approach, and pre-biometrics data sets would have to be backfilled with biometric data for this approach to be successfully implemented.
- Another emerging approach to data linkage includes tokenization, which substitutes sensitive-data elements with non-sensitive elements upon which the linkage is made.
These identifiers or “tokens” are then mapped back to the original data by a tokenization system that conforms to security best practices.
- In terms of analytics developments for which interoperability is a key enabler, we would also like to mention federated learning.
Briefly stated, this emerging approach contains a paradigm in which data remain decentralized with multiple hosts, and learning algorithms are trained across hosts without data exchange. To accomplish this, common data models are typically developed and implemented to make data interoperable, thus ensuring that differences in structure, format, or semantics across hosts do not bias results.
Will FHIR Become the Future of Interoperability?
While the evolution in healthcare IT is relatively slow compared to other domains such as consumer tech, we see very strong momentum building behind the use of FHIR.
In fact, in our opinion FHIR is well positioned to become an important future standard, based on these three factors:
- The increasing interconnectivity between health IT systems.
- The larger role of tech generalists
- Regulatory pressure.
- The increasing interconnectivity between health IT systems.
Originally, EMRs were the center of the health IT universe. Very few additional systems were able to export and import only to and from EMRs — and even then using only a small number of predefined types of documents. Today, however, a great deal of information can be gathered outside of clinical encounters such as through wearables, patient questionnaires, or mobile apps. An expanding array of such sources dictates the need for one simpler standard that can be implemented across a variety of platforms and that allows data exchanges that bypass EMRs.

2. The larger role of tech generalists
Technology “generalist” organizations continue to be interested in the healthcare IT space. This influx of outside expertise will benefit approaches that are most aligned with general trends in software development and architecture. Indeed, Apple is one of the backers of the Argonaut Project, the leading industry partnership promoting FHIR in the payer/provider space. Apple also uses FHIR to ingest data into their Health Records iPhone app from partnering medical centers. On the cloud infrastructure side, both Google Cloud and AWS fully support FHIR in their Healthcare API offerings.
3. Regulatory pressure.
Government support is a great boost for any healthcare standard, and FHIR seems to be gaining momentum here as well. For example, CMS has rolled out the FHIR 2021 interoperability mandate that requires all the providers it regulates to implement the FHIR R4-based API so that patients can retrieve their claims, encounters, and cost information.
Given the above, we anticipate that FHIR is well positioned to become the interoperability standard of choice, particularly for newly built systems and architectures.
About the authors
Yegor Smurnyy
Senior Data Scientist, BCG Gamma
Mathias Blom
Senior Data Scientist, BCG Gamma
Satty Chandrashekhar
Managing Director & Partner, BCG
Originally published at https://medium.com on February 1, 2021.
PDF of the scientific paper:
Harmonization of the ICHOM Quality Measures to Enable Health Outcomes Measurement in Multimorbid…
Objectives: To update the sets of patient-centric outcomes measures (“standard-sets”) developed by the not-for-profit…www.frontiersin.org








