




What is the message?
The success of machine learning models heavily relies on high-quality datasets, but labeling errors are common, especially in healthcare.
This summary explores the significance of active label cleaning in mitigating the adverse effects of noisy datasets, particularly in healthcare applications, and presents strategies to optimize label quality under resource constraints.
EXECUTIVE SUMMARY
What are the key points?
Challenges of Labeling Errors: Labeling errors arise from various sources such as automated extraction, ambiguities, and human errors, leading to biases and inaccurate model predictions.
Importance of Label Cleaning: Cleaning labels is essential for improving both model training and evaluation, as it enhances generalization and ensures accurate performance assessment.
Resource Constraints: Due to limited resources, it’s impractical to review every sample manually, necessitating prioritization strategies for efficient label cleaning.
Active Label Cleaning Framework: The proposed framework prioritizes samples based on difficulty and potential error impact, optimizing the allocation of resources for relabeling efforts.
Complementary Approaches: Active label cleaning complements robust-learning and self-supervision techniques, enhancing model robustness and performance under noisy conditions.
Practical Considerations: Human-in-the-loop monitoring ensures intervention when necessary, maintaining the integrity of the label cleaning process.
What are the key examples?
The NIH ChestXray dataset exemplifies the challenge of labeling errors in large healthcare datasets, underscoring the need for efficient label cleaning strategies.
The active label cleaning framework demonstrates substantial savings in relabeling efforts while improving label quality, crucial for model validation in healthcare applications.
What are the key statistics?
The proposed active label cleaning framework could potentially prevent 39 million premature deaths from non-communicable diseases, with an estimated economic benefit outweighing costs 19:1.
Simulation results indicate significant resource savings and improved downstream performance with the active label cleaning approach compared to random selection methods.
Conclusion
Active label cleaning presents a viable solution to mitigate the adverse effects of labeling errors in machine learning, particularly in healthcare.
By prioritizing samples based on difficulty and impact, this approach optimizes the allocation of resources, ensuring accurate model training and evaluation.
Embracing active label cleaning frameworks is imperative for developing robust and reliable machine learning models in resource-constrained settings.
DEEP DIVE

Active label cleaning for improved dataset quality under resource constraints (e.g. Healthcare)
Nature Communications
Mélanie Bernhardt, Daniel C. Castro, Ryutaro Tanno, Anton Schwaighofer, Kerem C. Tezcan, Miguel Monteiro, Shruthi Bannur, Matthew P. Lungren, Aditya Nori, Ben Glocker, Javier Alvarez-Valle & Ozan Oktay
March 4, 2022
Introduction
The success of supervised machine learning primarily relies on the availability of large datasets with high-quality annotations. However, in practice, labelling processes are prone to errors, almost inevitably leading to noisy datasets-as seen in ML benchmark datasets 1.
The success of supervised machine learning primarily relies on the availability of large datasets with high-quality annotations. However, in practice, labelling processes are prone to errors, almost inevitably leading to noisy datasets-as seen in ML benchmark datasets
Labelling errors can occur due to automated label extraction 2,3, ambiguities in input and output spaces 4, or human errors 5(e.g. lack of expertise).
At training time, incorrect labels hamper the generalisation of predictive models, as labelling errors may be memorised by the model resulting in undesired biases 6,7.
At test time, mislabelled data can have detrimental effects on the validity of model evaluation, potentially leading to incorrect model selection for deployment as the true performance may not be faithfully reflected on noisy data.
Label cleaning is therefore crucial to improve both model training and evaluation.
Labelling errors can occur due to automated label extraction 2,3, ambiguities in input and output spaces 4, or human errors 5 (e.g. lack of expertise).
Label cleaning is therefore crucial to improve both model training and evaluation
Relabelling a dataset involves a laborious manual reviewing process and in many cases the identification of individual labelling errors can be challenging. It is typically not feasible to review every sample in large datasets.
Consider for example the NIH ChestXray dataset 3, containing 112 k chest radiographs depicting various diseases.
Diagnostic labels were extracted from the radiology reports via an error-prone automated process8.
Later, a subset of images (4.5 k) from this dataset were manually selected and their labels were reviewed by expert radiologists in an effort driven by Google Health2.
Similarly, 30 k randomly selected images from the same dataset were relabelled for the RSNA Kaggle challenge9.
Such relabelling initiatives are extremely resource-intensive, particularly in the absence of a data-driven prioritisation strategy to help focusing on the subset of the data that most likely contains errors.
Relabelling a dataset involves a laborious manual reviewing process and in many cases the identification of individual labelling errors can be challenging. It is typically not feasible to review every sample in large datasets.
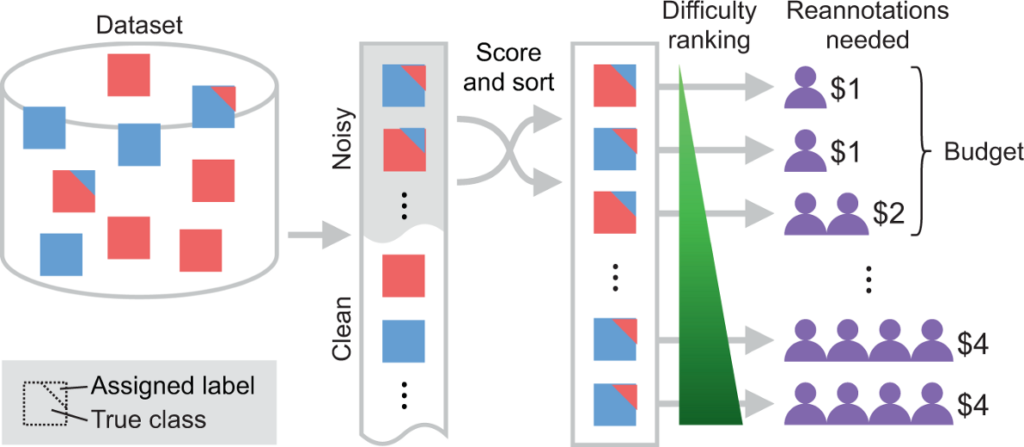
Due to the practical constraints on the total number of re-annotations, samples often need to be prioritised to maximise the benefits of relabelling efforts (see Fig. 1), as the difficulty of reviewing labelling errors can vary across samples.
Some cases are easy to assess and correct, others may be inherently ambiguous even for expert annotators (Fig. 2).
Due to the practical constraints on the total number of re-annotations, samples often need to be prioritised to maximise the benefits of relabelling efforts (see Fig. 1), as the difficulty of reviewing labelling errors can vary across samples.
For such difficult cases, several annotations (i.e. expert opinions) may be needed to form a ground-truth consensus 2,10, which comes with increasing relabelling “cost”.
Hence, there is a need for relabelling strategies that consider both resource constraints and individual sample difficulty-especially in healthcare, where availability of experts is limited and variability of annotations is typically high due to the difficulty of the tasks11.
Hence, there is a need for relabelling strategies that consider both resource constraints and individual sample difficulty-especially in healthcare, where availability of experts is limited and variability of annotations is typically high due to the difficulty of the tasks
Fig. 1: Overview of the proposed active label cleaning.
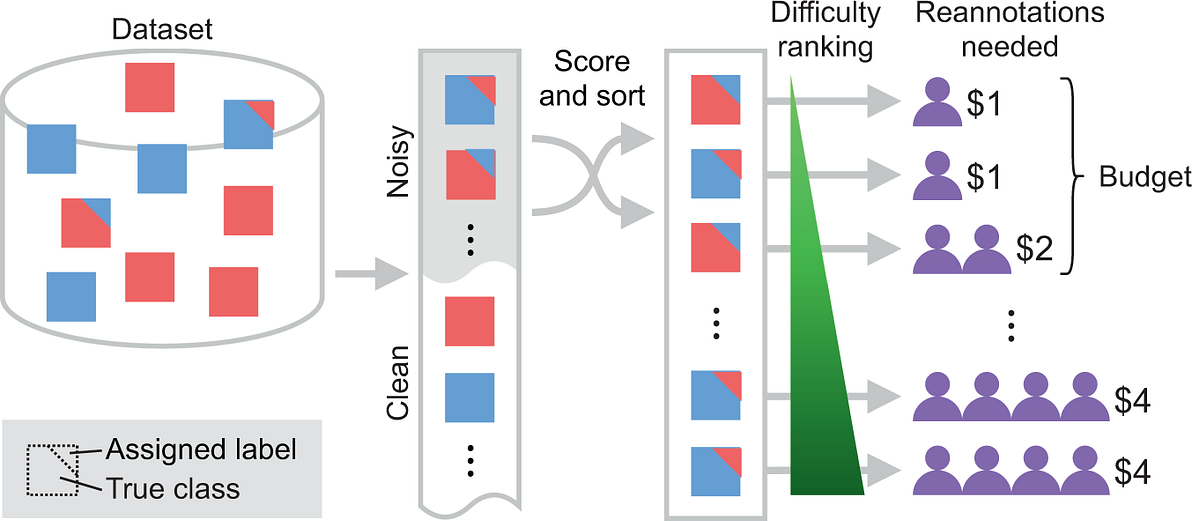
A dataset with noisy labels is sorted to prioritise clearly mislabelled samples, maximising the number of corrected samples given a fixed relabelling budget.
Fig. 2: Image labelling can become difficult due to ambiguity in input space26.
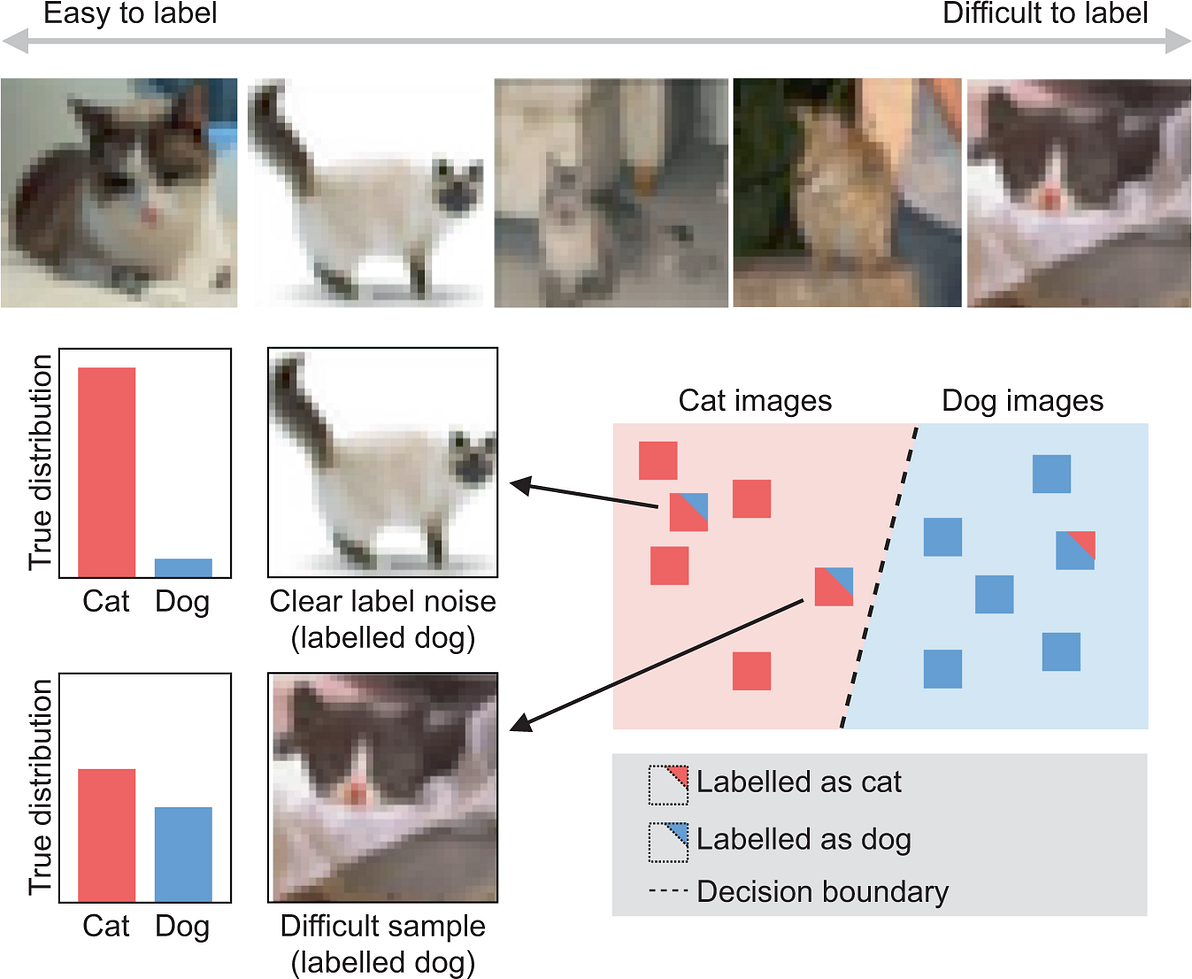
Top row shows the spectrum of ambiguity for cat images sampled from CIFAR10H dataset. The 2D plot illustrates different types of mislabelled samples: clear noise and difficult cases. We expect the former to be adjacent to semantically similar samples with a different label, and the latter to be closer to the optimal decision boundary.
While there are learning approaches designed specifically to handle label noise during training, we claim that these strategies can benefit from active labelling for two main reasons:
While there are learning approaches designed specifically to handle label noise during training, we claim that these strategies can benefit from active labelling for two main reasons:
First, clean evaluation labels are often unavailable in practice, in which case one cannot reliably determine whether any trained model is effective for a given real-world application.
In that regard, active label collection can iteratively provide useful feedback to NRL approaches.
Second, NRL approaches often cope with noise by inferring new labels 12 or disregarding samples 13 that could otherwise be highly informative or even be correctly labelled.
However, models trained with these approaches can still learn biases from the noisy data, which may lead them to fail to identify incorrect labels, flag already correct ones, or even introduce additional label noise via self-confirmation.
Active label cleaning complements this perspective, aiming to correct potential biases by improving the quality of training dataset and preserving as many samples as possible.
This is imperative in safety-critical domains such as healthcare, as model robustness must be validated on clean labels.
Prioritising samples for labelling also underpins the paradigm of active learning, whose goal is to select unlabelled samples that would be most beneficial for training in order to improve the performance of a predictive model on a downstream task.
The key difference here for the proposed approach is that our goal is not only to improve model performance but also to maximise the quality of labels given limited resources, which makes it valuable for both training and evaluation of predictive models. In more detail, we demonstrate how active learning and NRL can play complementary roles in coping with label noise.
Prioritising samples for labelling also underpins the paradigm of active learning,…
The key difference here for the proposed approach is that our goal is not only to improve model performance but also to maximise the quality of labels given limited resources, …
In this work, we begin by defining the active label cleaning setting in precise terms, along with the proposed relabelling priority score.
Using datasets of natural images and of chest radiographs, we then demonstrate experimentally the negative impacts of label noise on training and evaluating predictive models, and how cleaning the noisy labels can mitigate those effects.
Third, we show via simulations that the proposed active label cleaning framework can effectively prioritise samples to re-annotate under resource constraints, with substantial savings over naive random selection.
Fourth, we analyse how robust-learning 14 and self-supervision 15 techniques can further improve label cleaning performance.
Lastly, we validate our choice of scoring function, which accounts for sample difficulty and noise level, comparing with an active learning baseline.
Results
See the original publication.
In summary, label noise can negatively affect not only model building, but also validation. The latter is especially relevant in high-risk applications, e.g. for the regulation of models in healthcare settings.
Our results in later sections demonstrate how active cleaning of noisy training and evaluation labels can help mitigate such issues.
Discussion
This work investigated the impact of label noise on model training and evaluation procedures by assessing its impact in terms of (I) predictive performance drop, (II) model evaluation results, and (III) model selection choices.
As potential ways to mitigate this problem can be resource-demanding depending on the application area, we defined cost-effective relabelling strategies to improve the quality of datasets with noisy class labels.
These solutions are benchmarked in a specifically-devised simulation framework to quantify potential resource savings and improvement in downstream use-cases.
In particular, we highlight the importance of cleaning labels in a noisy evaluation set.
We showed that neglecting this step may yield misleading performance metrics and model rankings that do not generalise to the test environment.
This can, in turn, lead to overoptimistic design decisions with negative consequences in high-stakes applications such as healthcare.
One of our main findings is that the patterns of label error in the data (i.e., structural assumptions about label errors shown in Fig. 6) can have as large an impact on the efficacy of label cleaning and robust-learning methods as the average noise rates, as evidenced by the results obtained on both training and validation sets.
We therefore recommend carefully considering the underlying mechanisms of label noise when attempting to compare possible solutions.
We therefore recommend carefully considering the underlying mechanisms of label noise when attempting to compare possible solutions.
Note that, when cleaning the test set, there may be concerns about introducing dependency between the training and test sets.
To avoid this, selector models utilised for sample prioritisation should ideally (i) be trained solely on the test set and (ii) not be used for classification and evaluation purposes.
Moreover, it is worth noting that modelling biases could be reflected in the ranking of the samples.
Such biases may be mitigated by employing an ensemble of models with different formulations and inductive biases for posterior estimation in Eq. ( 2), as the framework makes no assumptions about the family of functions that can be used for label cleaning.
Note that, when cleaning the test set, there may be concerns about introducing dependency between the training and test sets.
To avoid this … the authors make some recommendations
The results also suggest that even robust-learning approaches may not fully recover predictive performance under high noise rates. In such cases, SSL pre-training is experimentally shown to be a reliable alternative, outperforming noise-robust models trained from scratch, even more so with the increasing availability of unlabelled datasets.
The results also suggest that even robust-learning approaches may not fully recover predictive performance under high noise rates. In such cases, SSL pre-training is experimentally shown to be a reliable alternative …
Lastly, we show that acquiring new labels can complement NRL by recycling data samples even if their labels are noisy, and can also handle biased labels.
Thus, the two domains can be combined to obtain not only a better model, but also clean data labels for downstream applications.
Lastly, we show that acquiring new labels can complement NRL by recycling data samples …
Thus, the two domains can be combined …
A limitation of data-driven approaches for handling label noise is that they may still be able to learn from noise patterns in the data when label errors occur in a consistent manner. As such, some mislabellings may remain undetected.
A limitation of data-driven approaches for handling label noise is that they may still be able to learn from noise patterns in the data when label errors occur in a consistent manner. As such, some mislabellings may remain undetected.
However, it is worth noting that our approach does not flip already correct labels
From this perspective, the proposed algorithm will converge towards the true label distribution
However, it is worth noting that our approach does not flip already correct labels (assuming that manual labellers provide i.i.d. samples from the true data distribution).
From this perspective, the proposed algorithm will converge towards the true label distribution (with a sufficient number of labels), addressing label inconsistencies detectable by the selector model while optimising for the objective given in Eq. ( 1).
Under extreme conditions where the bounded noise rate assumption may not hold (i.e. where on average there are more incorrect labels than correct in a given dataset), random selection can become preferable over data-driven approaches 38.
Under extreme conditions where the bounded noise rate assumption may not hold… random selection can become preferable over data-driven approaches
However, in the case of bounded noise rate-as in most real-world applications-the active learning component of the proposed framework can potentially address such consistent noise patterns in labels 38.
Indeed, the proposed active approach enables establishing a distilled set of expert labels to tackle this challenge, instead of solely relying on self-distillation or hallucination of the true labels as in NRL methods 38.
Indeed, the proposed active approach enables establishing a distilled set of expert labels to tackle this challenge, instead of solely relying on self-distillation or hallucination of the true labels as in NRL methods
To further extend our methodology along these lines, one could treat the newly acquired labels as expert-distilled samples, and rely more heavily on them for posterior updates in the proposed iterative framework.
To further extend our methodology along these lines, one could treat the newly acquired labels as expert-distilled samples, and rely more heavily on them for posterior updates in the proposed iterative framework.
Lastly, recall that the proposed label cleaning procedure is a human-in-the-loop system. Therefore, from a practical point-of-view, the process can be monitored and intervened upon whenever assumptions may be violated or if there is a concern around mislabelling biases in the dataset.
Lastly, recall that the proposed label cleaning procedure is a human-in-the-loop system. Therefore, from a practical point-of-view, the process can be monitored and intervened upon whenever assumptions may be violated or if there is a concern around mislabelling biases in the dataset.
Although the present study focused on imaging, the proposed methodology is not limited to this data modality, and empirical validation with other input types is left for future work.
It will also be valuable to explore, for example, having the option to also annotate unlabelled samples, or actively choosing the next annotator to label a selected instance.
Such extensions to active cleaning will significantly broaden its application scope, enabling more reliable deployment of machine learning systems in resource-constrained settings.
Here, we assume that the majority vote was representative of the ground truth. However, in some cases majority vote can become suboptimal when annotators have different levels of experience in labelling data samples 10.
For these circumstances, future work could explore sample selection objectives and label assignment taking into account the expertise of each annotator. Similarly, multi-label fusion techniques 39,40,41,42 can be used within the proposed label cleaning procedure to restore true label distribution by modelling labelling process and aggregating multiple noisy annotations.
Such approaches critically rely on the availability of multiple labels for each sample-which can be realised towards the end of relabelling efforts.
Methods
See the original publication
Funding
This work was funded by Microsoft Research Ltd (Cambridge, UK). The authors would also like to extend their thanks to Hannah Murfet for guidance offered as part the compliance review of the datasets used in this study.
About the authors
- Health Intelligence, Microsoft Research Cambridge, Cambridge, CB1 2FB, UK
- Mélanie Bernhardt, Daniel C. Castro, Ryutaro Tanno, Anton Schwaighofer, Kerem C. Tezcan, Miguel Monteiro, Shruthi Bannur, Aditya Nori, Ben Glocker, Javier Alvarez-Valle & Ozan Oktay
- Department of Radiology, Stanford University, Palo Alto, CA, 94304, USA
- Matthew P. Lungren
References and additional information
See original publication
Cite this article
Bernhardt, M., Castro, D.C., Tanno, R. et al. Active label cleaning for improved dataset quality under resource constraints. Nat Commun 13, 1161 (2022). https://doi.org/10.1038/s41467-022-28818-3
Originally published at https://www.nature.com on March 4, 2022.







