Site editor:
Joaquim Cardoso MSc
Health Transformation — institute for research and strategy
October 6, 2022
MIT Technology Review
Produced in partnership with Databricks
2022
This is an excerpt of the report “CIO vision 2025: Bridging the gap between BI and AI”, focusing on the Chapter 4 “Meeting the challenges of scale”, with the title above.
Meeting the challenges of scale (Chapter 4)
For all their development of AI use cases, companies have often found the generation of benefits from them to fall short of expectations.
A common refrain among technology leaders is that AI use cases have proven difficult to scale.
For S&P Global’s Swamy Kocherlakota, this remains the principal challenge to surmount in the years to come.
“We’re spending a lot of time trying to work out how we can apply our AI, machine learning, and NLP models at scale,” he says.
The survey respondents cite
- internal rigidity — of organizational structures and of processes — along with budget constraints for new technologies — as likely impediments to their plans for expanding and scaling AI use cases (respondents in North America are particularly concerned about being held back by structural rigidities).
Other constraints also loom large:
- limitations of existing data and AI technologies (cited most frequently by Asia-Pacific respondents) and
- shortages of AI-qualified talent (see Figure 3, page 11).
Figure 3: The likely impediments to companies’ ability to achieve their future goals for AI and machine learning (top responses; % of respondents)
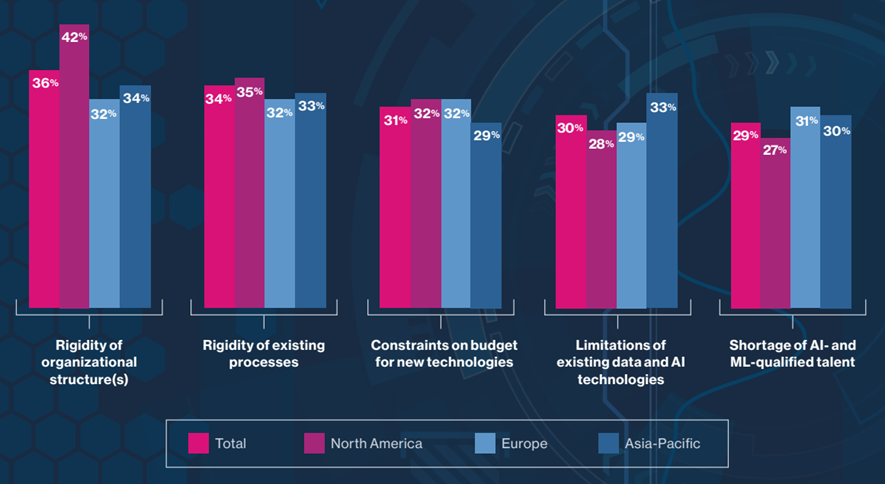
Source: MIT Technology Review Insights survey, 2022
Elsewhere, the respondents emphasize the data challenges they face in the endeavor to embed AI more firmly in their business:
- 72% say that problems with data are more likely than other factors to jeopardize the achievement of their AI goals between now and 2025.
Mike Maresca, global chief technology officer at pharmaceutical retailer Walgreens Boots Alliance, places data at the top of the list of AI challenges the company needs to address, even after having upgraded its data infrastructure.
“We now have the right data platform, the right quality tools, and the right governance in place,” he says.
“But ensuring the data quality remains high, while we enhance our algorithms over time to continue driving right business outcomes, is a key challenge as we scale.”
That view is echoed by Rowena Yeo of Johnson & Johnson:
“Data is one of the biggest challenges we face in [scaling AI], all the way from data acquisition to ingesting data, to managing it, and to ensuring the quality of the data.”
“Data is one of the biggest challenges we face in [scaling AI], all the way from data acquisition to ingesting data, to managing it, and to ensuring the quality of the data.”
Such concerns help explain why the survey respondents believe that, after development of their AI talent and skills base, their future investments in improving data quality will be the most instrumental of a series of steps taken to progress their AI use cases.
… after development of their AI talent and skills base, their future investments in improving data quality will be the most instrumental of a series of steps taken to progress their AI use cases.
Figure 4: The most instrumental investments in helping companies to generate benefits from AI (% of respondents)
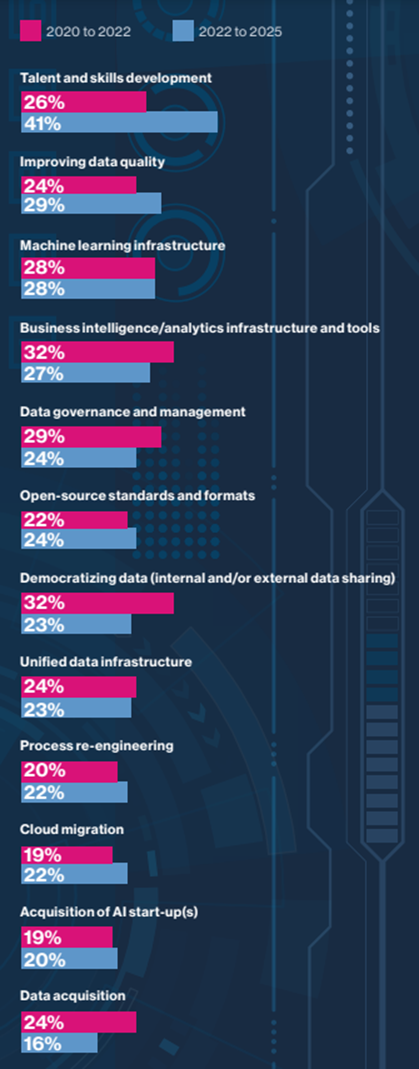
Source: MIT Technology Review Insights survey, 2022
For Jeremy Pee of Marks & Spencer, the data challenges of scaling extend further:
“One part of the challenge is building the infrastructure, building the data confidence, making it searchable, findable, trusted, and well-governed.
The other part is making it efficient for your data scientists to build intelligence and production scalability.
How do you go from a single model to building and supporting hundreds of them? If you don’t solve this part, you just end up creating a lot of inefficiency and frustration. The result — trust starts to break down.”
“One part of the challenge is building the infrastructure, building the data confidence, making it searchable, findable, trusted, and well-governed.
The other part is making it efficient for your data scientists to build intelligence and production scalability.
Next, we examine how companies plan to solidify the data foundations for the next phases of their AI development.
“Enabling the ‘democratization’ of AI involves building a set of algorithmic platforms that have intuitive front ends.” — Vittorio Cretella, Chief Information Officer, P&G
Procter & Gamble (P&G): Automating to scale
How does a multinational company that has already implemented a few hundred AI use cases develop and scale over a thousand of them? For P&G, the answer lies in automation.
“We aim to develop more and more AI use cases over the next couple of years,” says Vittorio Cretella.
“To do that, we need to automate the entire AI lifecycle, including data integration, model development, and model maintenance.”
Amid steady spending levels across most of P&G’s data and IT operations, automating AI will be a focus of new investment in the coming months and years, he says.
In Cretella’s vision, AI automation will enable greater use-case scale in multiple ways.
- One is through the building of automation toolkits and workbenches that will boost the efficiency of model building and management.
- Machine-learning suites available from cloud hyper-scalers (such as Microsoft, Google and Amazon) will help, but P&G’s approach will also involve plugging in solutions from start-ups and open-source platforms as well as some developed internally, says Cretella.
- “Automation will allow us to deliver more models with consistent quality while effectively managing bias and risk,” he says.
P&G’s automation strategy also aims to unleash the human dimension of use-case development, says Cretella. He explains:
“We have around 200 data scientists working on use cases in each of our business lines, but that’s not enough to build the scale that we need.
We need to allow a larger group of employees to configure key algorithms.”
Enabling such “democratization” of AI involves building a set of algorithmic platforms that have intuitive front ends.
“This means that business analysts can define the algorithm parameters and choose the features,” says Cretella. “We don’t need data scientists to do the coding.”
“We have around 200 data scientists working on use cases in each of our business lines, but that’s not enough to build the scale that we need. … business analysts can define the algorithm parameters and choose the features,” … “We don’t need data scientists to do the coding.”
The company has a successful model to guide the development of such platforms.
This is its recently patented, centralized “neighborhood analytics” platform, which Cretella describes as a “complex, multimodel algorithmic solution that clusters stores and neighborhoods based on consumer demographic and on demand and consumption signals.”
It is used for a multitude of sales, marketing, distribution, and other use cases in each individual store area, says Cretella.
Data scientists and analysts in every part of the business have access to the platform.
Building modelling capabilities on top of it that allow non-scientists to configure and run standard AI models at scale has furthered democratization.
The new platforms to come will expand such access, says Cretella.
“By lowering the entry barriers to employees to engage in model development,” it will also help P&G meet its ambitious goals for expanding AI use cases and generating greater value from them.
Originally published at: https://www.technologyreview.com
Names mentioned:
P&G, Vittorio Cretella.
For S&P Global’s Swamy Kocherlakota,
Mike Maresca, global chief technology officer at pharmaceutical retailer Walgreens Boots Alliance
Rowena Yeo of Johnson & Johnson
Jeremy Pee of Marks & Spencer,