the health strategist . institute
research and strategy institute — for continuous transformation
in health, care, cost and tech
Joaquim Cardoso MSc
Chief Researcher & Editor of the Site
March 31, 2023

Key Points
- On-site development of natural language processing methods that retrospectively unlock free-text databases of radiology clinics for data-driven medicine is of great interest.
- For clinics seeking to develop methods on-site for retrospective structuring of a report database of a certain department, it remains unclear which of previously proposed strategies for labeling reports and pre-training models is the most appropriate in context of, e.g., available annotator time.
- Using a custom pre-trained transformer model, along with a little annotation effort, promises to be an efficient way to retrospectively structure radiological databases, even if not millions of reports are available for pre-training.
ABSTRACT
Objectives
- To provide insights for on-site development of transformer-based structuring of free-text report databases by investigating different labeling and pre-training strategies.
Methods
- A total of 93,368 German chest X-ray reports from 20,912 intensive care unit (ICU) patients were included.
- Two labeling strategies were investigated to tag six findings of the attending radiologist.
- First, a system based on human-defined rules was applied for annotation of all reports (termed “silver labels”). Second, 18,000 reports were manually annotated in 197 h (termed “gold labels”) of which 10% were used for testing.
- An on-site pre-trained model (Tmlm) using masked-language modeling (MLM) was compared to a public, medically pre-trained model (Tmed).
- Both models were fine-tuned on silver labels only, gold labels only, and first with silver and then gold labels (hybrid training) for text classification, using varying numbers (N: 500, 1000, 2000, 3500, 7000, 14,580) of gold labels. Macro-averaged F1-scores (MAF1) in percent were calculated with 95% confidence intervals (CI).
Results
Tmlm,gold (95.5 [94.5–96.3]) showed significantly higher MAF1 than Tmed,silver (75.0 [73.4–76.5]) and Tmlm,silver (75.2 [73.6–76.7]), but not significantly higher MAF1 than Tmed,gold (94.7 [93.6–95.6]), Tmed,hybrid (94.9 [93.9–95.8]), and Tmlm,hybrid (95.2 [94.3–96.0]). When using 7000 or less gold-labeled reports, Tmlm,gold (N: 7000, 94.7 [93.5–95.7]) showed significantly higher MAF1 than Tmed,gold (N: 7000, 91.5 [90.0–92.8]). With at least 2000 gold-labeled reports, utilizing silver labels did not lead to significant improvement of Tmlm,hybrid (N: 2000, 91.8 [90.4–93.2]) over Tmlm,gold (N: 2000, 91.4 [89.9–92.8]).
Conclusions
- Custom pre-training of transformers and fine-tuning on manual annotations promises to be an efficient strategy to unlock report databases for data-driven medicine.
DEEP DIVE

Transformer-based structuring of free-text radiology report databases — European Radiology
European Radiology
S. Nowak, D. Biesner, Y. C. Layer, M. Theis, H. Schneider, W. Block, B. Wulff, U. I. Attenberger, R. Sifa & A. M. Sprinkart
11 March 2023
Introduction
Structured reporting, i.e., the use of IT-based systems for importing and arranging medical content in radiological reports, not only has the potential to have a positive impact on patient care by enhancing the quality of radiologists’ practices, it is also beneficial for the development of image-based artificial intelligence systems by helping to compile large retrospective patient collectives with diseases of interest [ 1, 2]. To this day, most radiological reports are in free-text and not in structured format. Even if a clinic would introduce structured reporting, retrospective assembling of large image collectives is labor-intensive, as the corresponding reports of recent years remain unstructured. Therefore, there is a need for automatic natural language processing (NLP) systems that categorize free-text reports in a set of predefined labels, thereby unlocking the corresponding image database for the development of an artificial intelligence-based diagnostic decision system.
To achieve automated analysis of medical text data, various methods with different levels of complexity have been proposed. For example, simple systems based on human-defined rules have been applied to automatically annotate the occurrence of findings in English chest X-ray reports [ 3]. These rule-based systems have the advantage that the method itself does not require any manually annotated reports. However, the creator of such a system must have considerable expert knowledge about general information, content, and wording of the reports. Moreover, there may still be findings whose appearance and description are subject to great variability, making the establishment of comprehensive rules a difficult task.
On the other hand, there are machine learning (ML)-based methods that have the disadvantage of requiring a large amount of time-consuming manual annotated reports for training. In recent years, transformer models based on the self-attention mechanism have emerged as the state-of-the-art ML-based NLP method, also for medical text data [ 4, 5, 6, 7, 8, 9]. The required amount of annotated data to train a transformer can be reduced by transfer learning, i.e., utilizing the fundamental text comprehension skills of a model that has already been pre-trained on different large public datasets and/or for another task.
In contrast to radiological image datasets, where the appearance of a finding, e.g., a pneumothorax, is independent of the country, the description of the finding in a radiological report can differ substantially, which is most obvious if the countries do not share a common language. For NLP, this limits the development and application of pre-trained models compared to computer vision applications, as, e.g., a model pre-trained on English reports cannot be directly applied to German texts. Moreover, unlike cross-sectional radiological images, text-based medical data contain sensitive information directly linked to personal data. This makes the public sharing of medical text data in compliance with data protection laws highly problematic in many countries [ 10]. Even when sharing pre-trained parameters of a transformer model trained on sensible data, it also cannot be ensured that data protection laws are met, as it has been shown that information from the training data can be extracted from large pre-trained transformers [ 11]. There are efforts to automate the de-identification of German text data using ML methods, from medical and other domains. However, currently, these methods cannot guarantee 100% accuracy [ 10, 12]. Consequently, efficient development of NLP models for structuring radiological reports on-site is of great interest.
Several approaches have already been presented for the on-site development of transformer models based on radiological text data. Two studies that are based on several hundred thousand English-language reports propose to employ a publicly available transformer pre-trained on medical text and to fine-tune that model in a two-step hybrid label approach. With the hybrid approach, the pre-trained model is first adapted to a high number of rule-based annotated text (termed “silver labels”) and then to only a very limited number of manual annotations (termed “gold labels”) [ 7, 8]. In contrast, another study proposes a custom pre-training of the transformer by MLM and next-sentence prediction using millions of radiology reports and subsequent fine-tuning to only a few gold-labeled reports [ 9].
However, for clinics seeking to develop NLP models on-site, it remains unclear which of those pre-training and labeling strategies are most appropriate for structuring their free-text radiological report database. First, it is not clear if a custom pre-training of transformer models is also beneficial with a significantly lower number of reports than in above-mentioned studies. Second, it is not clear whether the effort required to create a rule-based system for silver label generation in hybrid training is worthwhile compared to utilizing more gold labels by investing more annotator time. Therefore, the goal of this work is to provide insight and guidance for efficient retrospective structuring of radiological databases by systematically evaluating the performance of publicly available and custom pre-trained text-based transformers with respect to different labeling strategies and human annotation effort.
Materials and methods
Dataset and annotation
With institutional review board approval (AZ 411/21), written informed consent was waived, and approved data processing took place on the basis of the Health Data Protection Act North Rhine-Westphalia (GDSG NW) §6 (2) state law NRW. The retrospective dataset includes 93,368 free-text chest X-ray reports of 20,912 ICU patients (age: 62.7 ± 21.4, 8081 female) from University Hospital Bonn that were extracted consecutively from the radiological information system dating between December 2015 and July 2021.
First, 35 labels including not only findings but also further information, e.g., on indication, were defined for systematic annotation of the reports (see Supplement S1). Information on the interpretation of findings was not assessed from the reports. Under the supervision of a radiology resident (Y.C.L.), two medical research assistants labeled this information using the open-source software doccano [ 13]. The medical research assistants were trained to assign the correct labels based on the context of the free-text reports and not just on individual words. In case of ambiguity, they were instructed to consult the supervisor. Manually annotated gold labels were curated for 18,000 reports including only reports with unique admission numbers. A subset of six findings that are frequently raised during a patient’s ICU stay were selected from the entire label set. This selection was based on frequency of the finding and their clinical relevance and was made prior to NLP development. The NLP models were developed to predict the occurrence of these labels based on the report text via multi-label classification. These labels and their relative appearances within the gold-labeled reports are pulmonary infiltrates (20.0%), pleural effusion (45.6%), pulmonary congestion (34.0%), pneumothorax (3.8%), regular position of the central venous catheter (CVC) (45.8%), and misplaced position of the CVC (8.4%).
The 18,000 gold-labeled reports were randomly split into training set A (14,580), validation set B (1620), and test set C (1800). Additional 500 reports (test set D) were labeled by the radiology resident and both research assistants independently to determine the agreement between the annotators. This dataset was also used for the final test of the best NLP model with annotations of the radiology resident. Moreover, silver labels were created for a total of 91,068 reports applying a rule-based model which is described below. These are all available reports except the 1800 and 500 texts of the gold-labeled hold-out test sets C and D. Silver-labeled data were split into training set E (81,961) and validation set F (9107). Figure 1 shows an overview of the entire study.
Overview of the presented study. The dataset of the presented study includes a total of 93,368 free-text chest X-ray reports of intensive care unit patients. For a subset of the dataset, human annotations were generated for the occurrence of six findings within the reports to create gold-labeled training, validation, and test datasets. Furthermore, a rule-based system was applied for silver label generation. The use of an on-site pre-trained model using masked-language modeling (T mlm) was compared to a public, medically pre-trained model (T med) when adapting to silver labels only, gold labels only, and to first with silver and then gold labels (hybrid). To also give insights into which pre-training and labeling strategy is most appropriate in context of available human annotation time, the models were developed using varying numbers of gold-labeled reports
Rule-based model
A set of rules was defined to automatically annotate the free-text radiological reports. In short, the algorithm searches for specific terms, negations, and descriptions of uncertainty or applies further text-based rules in the “findings” section of the report. Detailed descriptions of the rule-based system can be found in Supplement S2.
Baseline NLP model
As a baseline NLP approach, we trained a term frequency-inverse document frequency (TFIDF) model on the training text and fitted a one-layer fully connected neural network to the labeled training data [ 14]. Training details can be found in Supplement S3.
Transformer-based model
We applied BERT as an established transformer model that has also been used in other work on medical text analysis [ 5, 7, 8, 9]. See Supplement S4 for details on the model architecture.
To investigate the impact of different pre-training strategies, we employed (i) a publicly available BERT language model that was pre-trained on (not annotated) German legal documents, Wikipedia, and news articles and then further adapted to medical articles and texts scraped from the web (T med) [ 15, 16, 17] and (ii) created a custom pre-trained BERT language model (T mlm) by applying MLM on the texts of train set E. To demonstrate the general effect of pre-training, we also trained a model from scratch for classification on gold-labeled text data without any pre-training (T rand,gold).
To examine the difference between different label strategies, three experiments were performed with the two pre-trained models. First, the pre-trained models were fine-tuned on the 14,580 gold labels of training set A only (T med,gold, T mlm,gold). Second, both pre-trained models were fine-tuned on silver-labeled training set E (T med,silver, T mlm,silver). Third, the models fine-tuned on silver-labeled training set E (T med,silver, T mlm,silver) were subsequently fine-tuned on training set A in a hybrid training (T med,hybrid, T mlm,hybrid). To investigate the effect of the number of available gold labels for fine-tuning, the models were also trained with limited numbers of gold-labeled reports of train set A (500, 1000, 2000, 3500, 7000 reports). All models were tested on test set C, and the best model was additionally tested on test set D.
When fine-tuning the models for text classification, we applied the following concepts. As proposed in previous studies, we fine-tuned all pre-trained models for text classification in two steps: First, frozen pre-trained language model parameters were used to adapt the new classification head and then all parameters were trained, but with layer-specific learning rates with maximum values increasing linearly from 10 −9to 10 −6from the first to the last layer [ 18, 19, 20]. Since the threshold for binarization of the predictions after sigmoid activation is not intrinsically set in multi-label classification, class-specific thresholds were determined by identifying the thresholds with the highest F1-scores on the training data [ 21]. Also, oversampling and loss weighting according to the occurrence of the classes within the training data were used to compensate for class imbalance. Classes that occurred in less than 25% of the training reports were duplicated until they accounted for at least 25%.
The pre-trained models fine-tuned for text classification on 14,580 and 7000 gold-labeled reports were trained for 75 epochs. Models that were fine-tuned on less than 7000 reports were trained with the same amount of optimization steps as the models trained on 7000 reports to ensure convergence. The pre-trained models that were fine-tuned on 81,961 silver-labeled reports were trained for 25 epochs.
For the custom pre-training via MLM, first, the BERT model was trained on 81,961 reports with a maximum learning rate of 10 −4and 15% of tokens masked for 150 epochs. After that, the model was further trained for 150 epochs with a maximum learning rate of 10 −5and 15% of whole words masked within the text. For custom pre-training, no weight decay was used.
For all models, the “bert-base-german-cased” tokenizer of the Huggingface’s transformer library was used and all models were trained using the Adam optimizer with decoupled weight decay regularization of 0.01, a learning rate scheme with warmup until 10% of all training steps and subsequent cosine decay, drop-out of 0.1, mixed precision, random seed 42, and a batch size of 24 on an NVIDIA RTX 3090 or NVIDIA TITAN RTX using PyTorch v1.8.1 and the transformers library v4.13.0 [ 15, 22]. The performance metrics were calculated using scikit-learn v0.24.2, and 95% CIs were calculated by bootstrapping with 1000 resamples for the text-classification models [ 23]. Performance differences were considered significant based on non-overlapping CIs.
Results
Time for manual annotation of 18,000 radiological reports was 197 h (39.4 s per report). The two medical research assistants’ annotations showed high agreement with the radiology resident’s annotations, with mean accuracy of 97.4% and 97.3% and MAF1 in percent of 92.9 and 93.5, respectively.
In the custom pre-training of BERT (T mlm), an accuracy of 88.6% was achieved after 3.3 days of training to predict 15% masked tokens and subsequently an accuracy of 78.4% was achieved after again 3.3 days of training to predict 15% masked whole words on test data set C.
Table 1 shows the performance of all examined models trained with all available silver- and/or gold-labeled text classification data. The highest performance was observed for T mlm,gold with a MAF1 in percent of 95.5 (CI: 94.5–96.3), which was significantly higher than that of the rule-based system (75.1 [73.6–76.5]), T med,silver (75.0 [73.4–76.5]), T mlm,silver (75.2 [73.6–76.7]), TFIDF gold (83.2 [81.3–85.1]), and T rand,gold (84.3 [82.5–86.0]). However, the performance was not significantly higher than that of T med,gold (94.7 [93.6–95.6]), T med,hybrid (94.9 [93.9–95.8]), and T mlm,hybrid (95.2 [94.3–96.0]).
Table 1 Model performances for different pre-training and labeling strategies using all training data
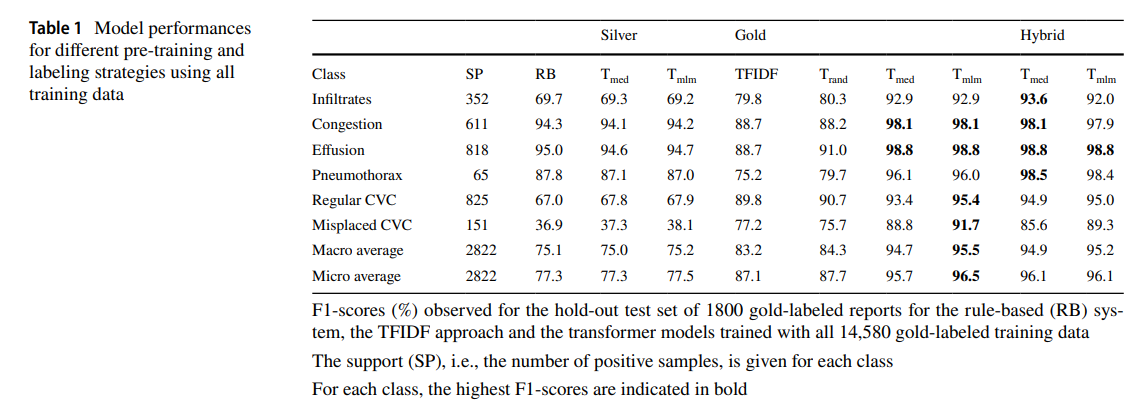
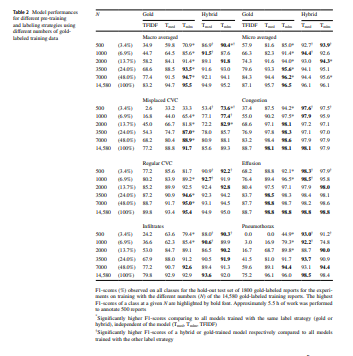
Table 2 and Fig. 2 show the performance of the examined models for all classes when using lower numbers of gold-labeled data. The classification of the description of a misplaced CVC was found to be the most challenging class with the lowest F1-scores for each method. Considering models trained exclusively with gold-labeled reports, T mlm,gold showed significantly higher MAF1 as well as misplaced CVC F1-scores than TFIDF gold and T med,gold when only 1000 to 7000 gold-labeled reports were provided for training. The hybrid models adapted on only 500 gold labels (T mlm,hybrid 90.4 [89.0–91.9], T med,hybrid 86.9 [85.1–88.5]) achieved already significantly higher MAF1 than the rule-based system (75.1 [73.6–76.5]). Considering both models trained with a hybrid label scheme, no significant differences in MAF1 and F1-scores for misplaced CVC were observed for T med,hybrid and T mlm,hybrid trained with 1000 or more gold labels. When using 2000 or more gold-labeled reports (22 h of annotation), the previous use of silver labels in hybrid training of the BERT models (T mlm,hybrid 91.8 [90.4–93.2], T med,hybrid 89.1 [87.6–90.6]) did not provide a significant improvement of MAF1 over the BERT models (T mlm,gold 91.4 [89.9–92.8], T med,gold 84.1 [81.7, 86.0]) trained directly on the gold-labeled reports. Due to less than 4% positive pneumothorax cases leading to wide CIs, F1-scores for pneumothorax of the rule-based system (87.8 [81.1–93.0]) are only significantly lower compared with T mlm,hybrid (98.4 [95.9–100.0]) and T med,hybrid (98.5 [96.0–100.0]) trained with all gold labels.
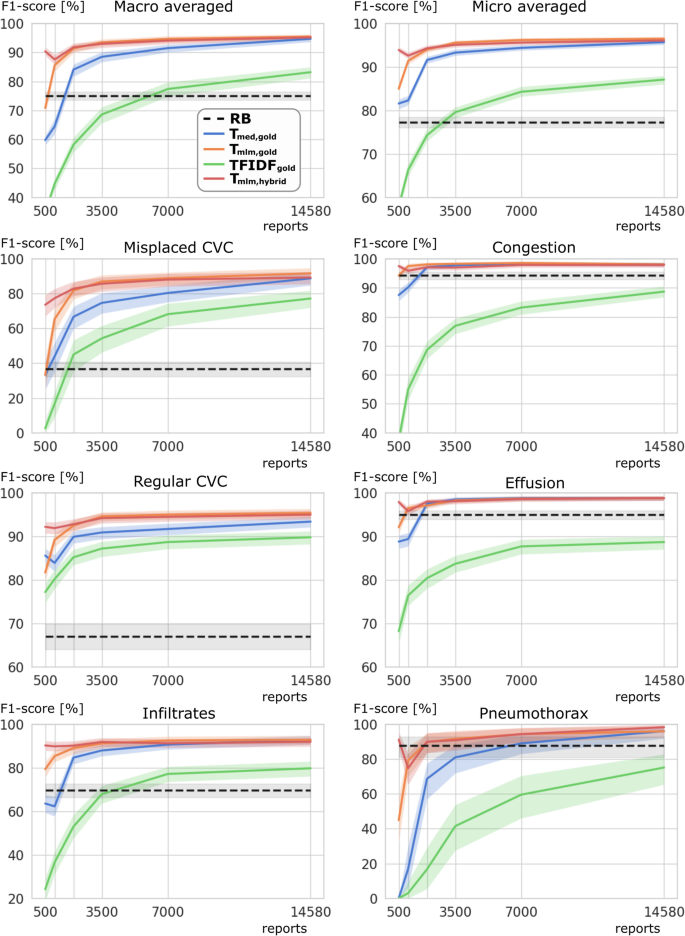
Table 2 Model performances for different pre-training and labeling strategies using different numbers of gold-labeled training data
Model performances for different numbers of gold-labeled reports. F1-scores in % ( y-axis) are displayed for the rule-based (RB) system in black, as well as for T med,gold (blue), T mlm,gold (orange), TFIDF gold (green), and T mlm,hybrid (red) using various numbers of gold-labeled reports for training ( x-axis)
Table 3 shows further performance metrics for the best model, T mlm,gold, which was pre-trained using MLM and fine-tuned to 14,580 gold labels that showed the highest MAF1 (95.5, CI: 94.5–96.3) and macro-averaged area under the receiver operating characteristic curve (MAAUC: 97.1, CI: 96.3–97.8) for test set C with 1800 cases, as well as for test set D with 500 cases (MAF1: 93.5, CI: 91.0–95.3; MAAUC: 95.7, CI: 93.8–97.1). Due to space limitations, CIs for each single value in Tables 1– 3 can be found in Supplement S5.
Table 3 Detailed model performance of Tmlm,gold for both test sets

Discussion
The current study investigates efficient on-site development of NLP methods in the context of different pre-training and labeling strategies for structuring and thus unlocking radiological databases for data-driven medicine using German ICU chest X-ray reports. The work provides clinics seeking to develop NLP models on-site with insights and guidance on which strategy is preferable for their specific project in the context of available annotator and developer time and the complexity of the information to be extracted. Methods for training transform-based NLP models will be provided upon reasonable request ( https://qilab.de).
The results show that when training with a large set of silver labels without the use of gold labels, the pre-trained BERT models achieved comparable performance to the rule-based system and are limited by the quality of the silver labels. By using a publicly available, medically pre-trained BERT with a hybrid label approach that was first adapted on all silver labels and then fine-tuned on a small set of gold-labeled reports, significantly higher performance can be achieved compared to the rule-based system. Both findings are in line with previous studies that used silver-labeled chest X-ray reports in the English language by CheXpert and further trained on 1000 manually curated reports or sentences [ 3, 7, 8]. However, when utilizing 2000 or more gold-labeled reports that were generated in only 22 h of annotation, the hybrid label approach did not provide a significant improvement over training the publicly available BERT model directly with the gold labels. The results of this work also show that the custom pre-training of BERT with only 81,961 reports can not only achieve high MLM accuracy compared to previous studies with millions of reports [ 9], but also demonstrate that this model achieves significantly higher performance than the publicly available pre-trained BERT model when further trained for report classification with 7000 or less gold labels.
The performance of the rule-based system that generates the silver labels varies strongly between the extracted classes. This can be explained by the fact that some information from the radiological reports have more variable attributes and are more difficult to identify by rules and standard formulations. In contrast to previous studies, we extracted information about a regular or misplaced position of the CVC from the findings. Especially, the formulations for a misplaced CVC appeared to be difficult to recognize with simple rules, in contrast to, e.g., pleural effusion and pulmonary congestion. Through further effort by clinicians and technicians, certainly more special cases could be covered by advanced rules, in order to further develop the simple rule-based labeler. However, this would require extensive reading and studying of the reports, during which gold labels could already be generated. With regard to the results of this study, it is therefore questionable whether for information with variable attributes and descriptions, the effort of developing advanced rules for a rule-based labeler is worthwhile compared to generating more gold labels with subsequent training of custom pre-trained transformers.
A limitation of the study is that annotation of the contents of the radiology reports was performed by medical research assistants under the supervision of a radiology resident. Because the annotators did not have to interpret imaging, but were simply required to identify and mark the statements of the attending radiologist within the report, we judged that annotation was not required to be conducted by board-certified radiologists. The high agreement of the different annotators confirmed this judgement, which minimized the cost of annotation and allowed for capturing a larger set of reports.
Conclusion
In conclusion, we find that an on-site custom pre-training of text-based transformers with subsequent adaptation to manually curated gold labels promises to be an efficient strategy to unlock radiological report databases for data-driven medicine.
Funding
Open Access funding enabled and organized by Projekt DEAL. S.R., B.W., D.B, and H.S. are affiliated with the Competence Center for Machine Learning Rhine-Ruhr, which is funded by the Federal Ministry of Education and Research of Germany (grant no. 01|S18038B). The authors gratefully acknowledge this support. The funders had no influence on the conceptualization and design of the study, data analysis and data collection, preparation of the manuscript, and the decision to publish.
Authors and Affiliations
- Department of Diagnostic and Interventional Radiology, University Hospital Bonn, Venusberg-Campus 1, 53127, Bonn, Germany
- S. Nowak, Y. C. Layer, M. Theis, W. Block, U. I. Attenberger & A. M. Sprinkart
- Fraunhofer Institute for Intelligent Analysis and Information Systems IAIS, Sankt Augustin, Germany
- D. Biesner, H. Schneider, B. Wulff & R. Sifa
Cite this article
Nowak, S., Biesner, D., Layer, Y.C. et al. Transformer-based structuring of free-text radiology report databases. Eur Radiol (2023). https://doi.org/10.1007/s00330-023-09526-y
Originally published at https://link.springer.com on March 11, 2023.