




the health strategist
research and strategy institute for continuous transformation
in value based health, care and tech
Joaquim Cardoso MSc
Chief Researcher & Editor of the Site
March 26, 2023
Key Messages:
- A new study from Open AI, OpenResearch, and U of Pennsylvania explored the impact of GPT technologies on the US Labor Market.
- Their method was to compare GPT-4 capabilities to job requirements and to assess what percentage of job tasks will be impacted.
- 80% of the U.S. workforce will have at least 10% of their job-related tasks impacted by GPTs
- More surprising, they found approx. 20% of the U.S. workforce will have at least 50% of their tasks impacted. This impact spanned all wage levels with higher-income jobs facing greater impact.
SELECTED IMAGE(S)

DEEP DIVE

GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
Arxiv
Tyna Eloundou, Sam Manning, Pamela Mishkin, Daniel Rock
22 Mar 2023
ABSTRACT
We investigate the potential implications of Generative Pre-trained Transformer (GPT) models and related technologies on the U.S. labor market.
- Using a new rubric, we assess occupations based on their correspondence with GPT capabilities, incorporating both human expertise and classifications from GPT-4.
- Our findings indicate that approximately 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of GPTs, while around 19% of workers may see at least 50% of their tasks impacted.
- The influence spans all wage levels, with higher-income jobs potentially facing greater exposure.
- Notably, the impact is not limited to industries with higher recent productivity growth.
- We conclude that Generative Pre-trained Transformers exhibit characteristics of general-purpose technologies (GPTs), suggesting that these models could have notable economic, social, and policy implications.
1.INTRODUCTION
As shown in Figure 1, recent years, months, and weeks have seen remarkable progress in the field of generative AI and large language models (LLMs).
While the public often associates LLMs with various iterations of the Generative Pre-trained Transformer (GPT), LLMs can be trained using a range of architectures, and are not limited to transformer-based models (Devlin et al., 2019). LLMs can process and produce various forms of sequential data, including assembly language, protein sequences and chess games, extending beyond natural language applications alone. In this paper, we use LLMs and GPTs somewhat interchangeably, and specify in our rubric that these should be considered similar to the GPT-family of models available via ChatGPT or the OpenAI Playground (which at the time of labeling included models in the GPT-3.5 family but not in the GPT-4 family). We examine GPTs with text- and code-generating abilities, use the term “generative AI” to additionally include modalities such as images or audio, and use “GPT-powered software” to cover tools built on top of GPTs or that combine GPTs with other generative AI models.
Our study is motivated less by the progress of these models alone though, and more by the breadth, scale, and capabilities we’ve seen in the complementary technologies developed around them.
The role of complementary technologies remains to be seen, but maximizing the impact of GPTs appears contingent on integrating them with larger systems (Bresnahan, 2019; Agrawal et al., 2021). While the focus of our discussion is primarily on the generative capabilities of GPTs, it is important to note that these models can also be utilized for various tasks beyond text generation. For example, GPTs can generate embeddings for custom search applications, as well as perform tasks such as summarization and classification.
To complement predictions of technology’s impacts on work and provide a framework for understanding the evolving landscape of language models and their associated technologies, we propose a new rubric for assessing LLM capabilities and their potential effects on jobs.
This rubric (A.1) measures the overall exposure of tasks to GPTs, following the spirit of prior work on quantifying exposure to machine learning (Brynjolfsson et al., 2018; Felten et al., 2018; Webb, 2020). We define exposure as a proxy for potential economic impact without distinguishing between labor-augmenting or labor-displacing effects. We employ human annotators and GPT-4 itself as a classifier to apply this rubric to occupational data in the U.S. economy, primarily sourced from the O*NET database.12
To construct our primary exposure dataset, we collected both human annotations and GPT-4 classifications, using a prompt tuned for agreement with a sample of labels from the authors.
We observe similar agreement levels in GPT-4 responses and between human and machine evaluations, when aggregated to the task level. This exposure measure reflects an estimate of the technical capacity to make human labor more efficient; however, social, economic, regulatory, and other determinants imply that technical feasibility does not guarantee labor productivity or automation outcomes. Our analysis indicates that approximately 19% of jobs have at least 50% of their tasks exposed when considering both current model capabilities and anticipated tools built upon them. Human assessments suggest that only 3% of U.S. workers have over half of their tasks exposed to GPTs when considering existing language and code capabilities without additional software or modalities. Accounting for other generative models and complementary technologies, our human estimates indicate that up to 49% of workers could have half or more of their tasks exposed to LLMs.
Our findings consistently show across both human and GPT-4 annotations that most occupations exhibit some degree of exposure to GPTs, with varying exposure levels across different types of work.
Occupations with higher wages generally present with higher exposure, a result contrary to similar evaluations of overall exposure to machine learning (Brynjolfsson et al., 2023). When regressing exposure measures on skillsets using O*NET’s skill rubric, we discover that roles heavily reliant on science and critical thinking skills show a negative correlation with exposure, while programming and writing skills are positively associated with GPT exposure. Following Autor et al. (2022a), we examine barriers to entry by “Job Zones” and find that occupational exposure to GPTs weakly increases with the difficulty of job preparation. In other words, workers facing higher (lower) barriers to entry in their jobs tend to experience more (less) exposure to GPTs.
We further compare our measurements to previous efforts documenting the distribution of automation exposure in the economy and find broadly consistent results.
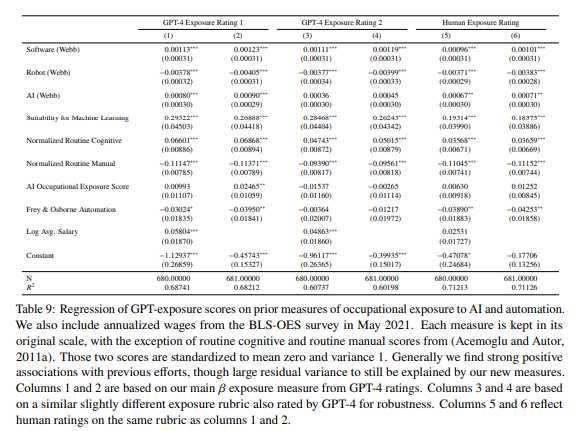
Most other technology exposure measures we examine are statistically significantly correlated with our preferred exposure measure, while measures of manual routineness and robotics exposure show negative correlations. The variance explained by these earlier efforts (Acemoglu and Autor, 2011a; Frey and Osborne, 2017; Brynjolfsson et al., 2018; Felten et al., 2018; Webb, 2020; Brynjolfsson et al., 2023), along with wage controls, ranges from 60 to 72%, indicating that 28 to 40% of the variation in our AI exposure measure remains unaccounted for by previous technology exposure measurements.
We analyze exposure by industry and discover that information processing industries (4-digit NAICS) exhibit high exposure, while manufacturing, agriculture, and mining demonstrate lower exposure.
The connection between productivity growth in the past decade and overall GPT exposure appears weak, suggesting a potential optimistic case that future productivity gains from GPTs may not exacerbate possible cost disease effects (Baumol, 2012; Aghion et al., 2018). 3
Our analysis indicates that the impacts of LLMs like GPT-4, are likely to be pervasive.
While LLMs have consistently improved in capabilities over time, their growing economic effect is expected to persist and increase even if we halt the development of new capabilities today.
We also find that the potential impact of LLMs expands significantly when we take into account the development of complementary technologies.
Collectively, these characteristics imply that Generative Pre-trained Transformers (GPTs) are general-purpose technologies (GPTs).4 (Bresnahan and Trajtenberg, 1995; Lipsey et al., 2005).
Our analysis indicates that the impacts of LLMs like GPT-4, are likely to be pervasive
(Goldfarb et al., 2023) argue that machine learning as a broad category is likely a general-purpose technology.
Our evidence supports a wider impact, as even subsets of machine learning software meet the criteria for general-purpose technology status independently.
This paper’s primary contributions are to provide a set of measurements of LLM impact potential and to demonstrate the use case of applying LLMs to develop such measurements efficiently and at scale.
Additionally, we showcase the general-purpose potential of LLMs.
If “GPTs are GPTs,” the eventual trajectory of LLM development and application may be challenging for policymakers to predict and regulate.
As with other general-purpose technologies, much of these algorithms’ potential will emerge across a broad range of economically valuable use cases, including the creation of new types of work (Acemoglu and Restrepo, 2018; Autor et al., 2022a).
Our research serves to measure what is technically feasible now, but necessarily will miss the evolving impact potential of the GPTs over time.
The paper is structured as follows:
- Section 2 reviews relevant prior work,
- Section 3 discusses methods and data collection,
- Section 4 presents summary statistics and results,
- Section 5 relates our measurements to earlier efforts,
- Section 6 discusses the results, and Section 7 offers concluding remarks.
Other Sections
See the original publication (this is an excerpt version only)
4.RESULTS (excerpt)
General-purpose technologies are relatively rare and characterized by their pervasiveness, improvement over time, and the development of significant co-invention and spillovers (Lipsey et al., 2005).
Our assessment of GPTs’ (Generative Pre-trained Transformers) or LLMs potential impact on the labor market is limited since it does not consider total factor productivity or capital input potential. In addition to their influence on labor, LLMs may also influence these dimensions. At this stage, some general-purpose technology criteria are easier to evaluate than others. Our primary focus at this early stage is to test the hypothesis that LLMs have a pervasive influence on the economy, similar to the approach taken by (Goldfarb et al., 2023), who analyzed machine learning diffusion through job postings to assess its status as a general-purpose technology. Instead of using job postings or studying machine learning in general, we employ the task evaluation approach with both human and GPT-4 annotations. This analysis may reveal whether the impacts are limited to a specific set of similar tasks or occupations or if they will be more widespread. Our findings suggest that, based on their task-level capabilities, GPTs have the potential to significantly affect a diverse range of occupations within the U.S. economy, demonstrating a key attribute of general-purpose technologies. In the following sections, we discuss results across various roles and wage structures. Additional results on the relative exposure of industries within the U.S. economy can be found in Appendix D. 10
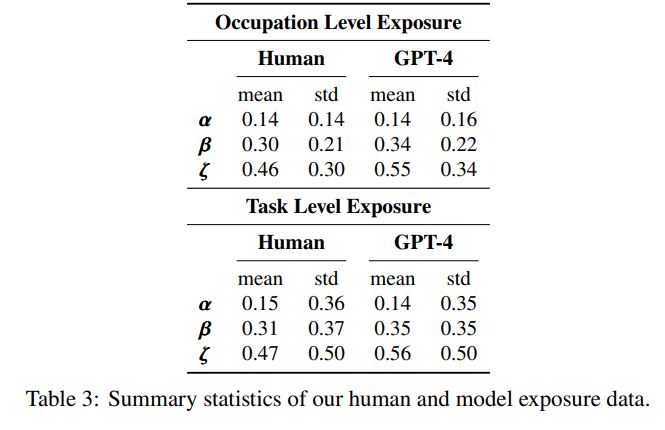
4.1 Summary Statistics
Summary statistics for these measures can be found in Table 3. Both human and GPT-4 annotations indicate that average occupation-level 𝛼 values fall between 0.14 and 0.15, suggesting that, on average, approximately 15% of tasks within an occupation are directly exposed to GPTs. This figure increases to over 30% for 𝛽 and surpasses 50% for 𝜁. Coincidentally, human and GPT-4 annotations also tag between 15% and 14% of total tasks in the dataset as being exposed to GPTs. Based on the 𝛽 values, we estimate that 80% of workers belong to an occupation with at least 10% of its tasks exposed to GPTs, while 19% of workers are in an occupation where over half of its tasks are labeled as exposed. We ran one set of analyses using O*NET’s “Importance” scores but did not find significant changes to our findings. Though we do acknowledge that not weighting relative importance of a task to a given occupation yields some curious results (e.g. ranking Barbers as having reasonably high exposure). Although the potential for tasks to be affected is vast, GPTs and GPT-powered software must be incorporated into broader systems to fully realize this potential. As is common with general-purpose technologies, coinvention barriers may initially impede the rapid diffusion of GPTs into economic applications. Furthermore, predicting the need for human oversight is challenging, especially for tasks where model capabilities equal or surpass human levels. While the requirement for human supervision may initially slow down the speed at which these systems diffuse through the economy, users of GPTs and GPT-powered systems are likely to become increasingly acquainted with the technology over time, particularly in terms of understanding when and how to trust its outputs.
4.2 Wages and Employment
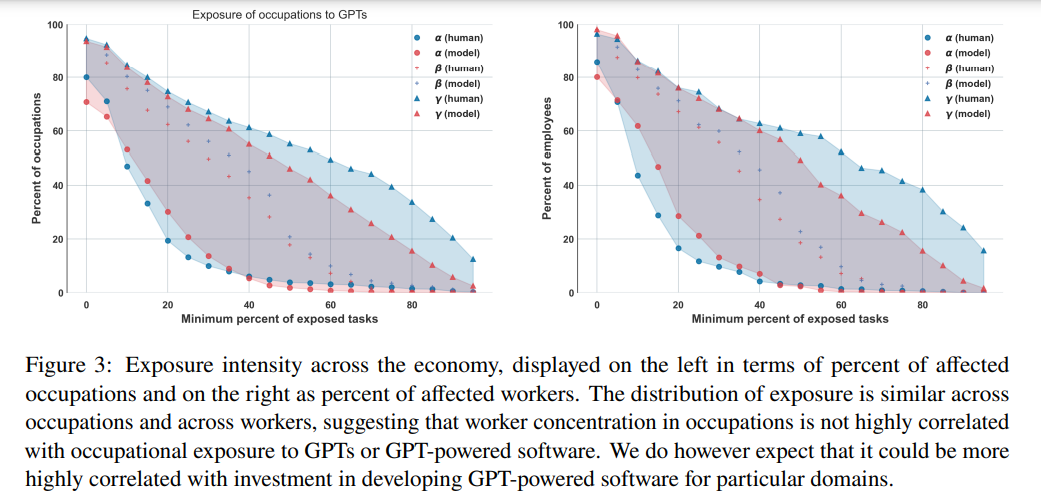
In Figure 3, we present the exposure intensity across the economy. The first plot displays exposure in terms of occupations, while the second plot shows exposure in terms of total workers. Each point on the graph represents the estimated percentage of workers (and occupations) on the y-axis with an exposure level (𝛼, 𝛽, and 𝜁) indicated on the x-axis. For example, human annotators determined that 2.4% of workers are 𝛼50-exposed, 18.6% are 𝛽50-exposed, and 49.6% are 𝜁50-exposed, where the threshold of 50% comes from the x-axis and the percentage of workers comes from the y axis in the right plot of Figure 2. At any given point on the x-axis, the vertical distance between the 𝛼 and the 𝜁 represents the exposure potential attributable to tools and applications beyond direct exposure to GPTs. The distribution of exposure is similar for both workers and occupations, suggesting that worker concentration in occupations does not have a strong correlation with occupational exposure to GPTs or GPT-powered software.
Aggregated at the occupation level, human and GPT-4 annotations exhibit qualitative similarities and tend to correlate, as demonstrated in Figure 4. Human annotations estimate marginally lower exposure for high-wage occupations compared to GPT-4 annotations. While there are numerous low-wage occupations with high exposure and high-wage occupations with low exposure, the overall trend in the binscatter plot reveals that higher wages are associated with increased exposure to GPT. The potential exposure to GPTs seems to have little correlation with current employment levels. In Figure 4, both human and GPT-4 ratings of overall exposure are aggregated to the occupation-level (y-axis) and compared with the log of total employment (x-axis). Neither plot reveals significant differences in GPT exposure across varying employment levels.
4.3 Skill Importance
In this section, we explore the relationship between the importance of a skill for an occupation (as annotated in the O*NET dataset) and our exposure measures.
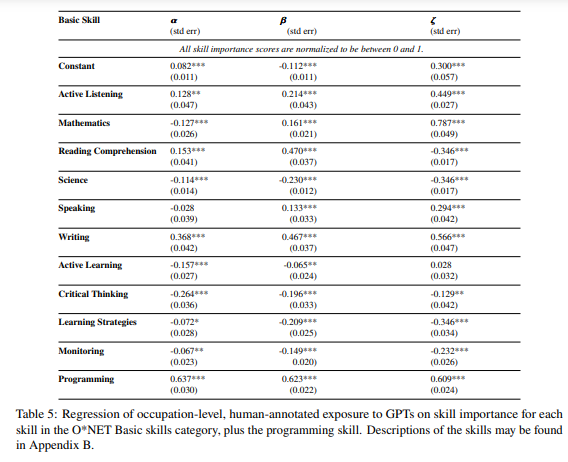
First, we use the Basic Skills provided by O*NET (skill definitions can be found in Appendix B) and normalize the measure of skill importance for each occupation to improve the comprehensibility of the results. Next, we conduct a regression analysis on our exposure measures (𝛼, 𝛽, 𝜁) to examine the strength of associations between skill importance and exposure. Our findings indicate that the importance of science and critical thinking skills are strongly negatively associated with exposure, suggesting that occupations requiring these skills are less likely to be impacted by current GPTs. Conversely, programming and writing skills show a strong positive association with exposure, implying that occupations involving these skills are more susceptible to being influenced by GPTs (see Table 5 for detailed results).
4.4 Barriers to Entry
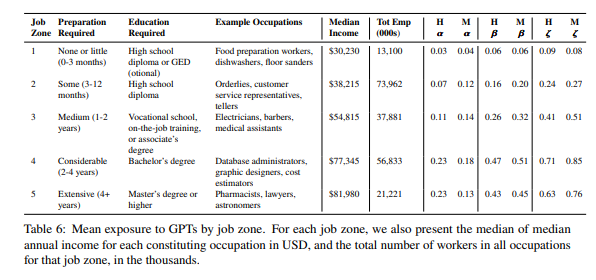
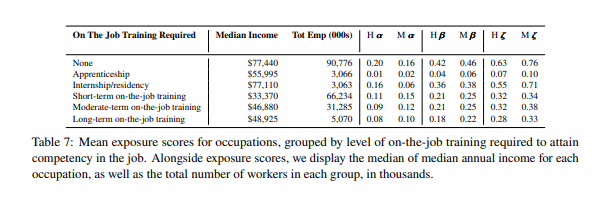
Next, we examine barriers to entry to better understand if there is differentiation in exposure due to types of jobs. One such proxy is an O*NET occupation-level descriptor called the “Job Zone.” A Job Zone groups occupations that are similar in (a) the level of education needed to get a job in the occupation, (b) the amount of related experience required to do the work, and © the extent of on-the-job training needed to do the work.
4.4.1 Typical Education Needed for Entry
Since inclusion in a Job Zone accounts for both the education required — which itself is a proxy for skill acquisition — and the preparation required, we seek data to disentangle these variables. We use two variables from the Bureau of Labor Statistics’ Occupational data: “Typical Education Needed for Entry” and “On-the-job Training Required to Attain Competency” in an occupation. By examining these factors, we aim to uncover trends with potential implications for the workforce. There are 3,504,000 workers for whom we lack data on education and on-the-job training requirements, and they are therefore excluded from the summary tables. Our analysis suggests that individuals holding Bachelor’s, Master’s, and professional degrees are more exposed to GPTs and GPT-powered software than those without formal educational credentials (see Table 7). Interestingly, we also find that individuals with some college education but no degree exhibit a high level of exposure to GPTs and GPT-powered software. Upon examining the table displaying barriers to entry, we observe that the jobs with the least exposure require the most training, potentially offering a lower payoff (in terms of median income) once competency is achieved. Conversely, jobs with no on-the-job training required or only internship/residency required appear to yield higher income but are more exposed to GPT.
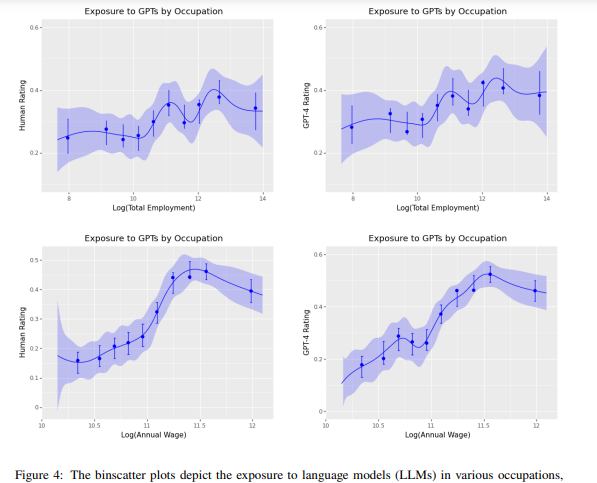
Figure 4: The binscatter plots depict the exposure to language models (LLMs) in various occupations, as assessed by both human evaluators and GPT-4. These plots compare the exposure to GPT (𝛽) at the occupation level against the log of total employment within an occupation and log of the median annual wage for occupations. While some discrepancies exist, both human and GPT-4 assessments indicate that higher wage occupations tend to be more exposed to LLMs. Additionally, numerous lower wage occupations demonstrate high exposure based on our rubric. Core tasks receive twice the weight of supplemental tasks within occupations when calculating average exposure scores. Employment and wage data are sourced from the BLS-OES survey conducted in May 2021.
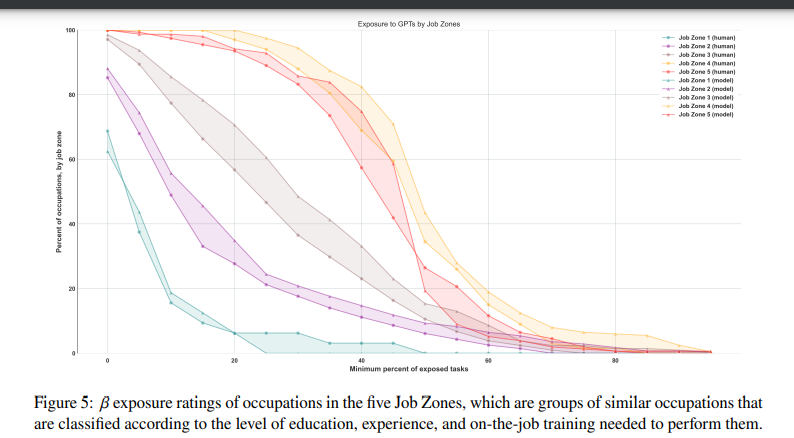
In the O*NET database, there are 5 Job Zones, with Job Zone 1 requiring the least amount of preparation (3 months) and Job Zone 5 requiring the most extensive amount of preparation, 4 or more years. We observe that median income increases monotonically across Job Zones as the level of preparation needed also increases, with the median worker in Job Zone 1 earning $30, 230 and the median worker in Job Zone 5 earning $80, 980. All of our measures (𝛼, 𝛽, and 𝜁) show an identical pattern, that is, exposure increases from Job Zone 1 to Job Zone 4, and either remains similar or decreases at Job Zone 5. Similar to Figure 3, in Figure 5, we plot the percentage of workers at every threshold of exposure. We find that, on average, the percentage of workers in occupations with greater than 50% 𝛽 exposure in Job Zones 1 through 5 have 𝛽 at 0.00% (Job Zone 1), 6.11% (Job Zone 2), 10.57% (Job Zone 3), 34.5% (Job Zone 4), and 26.45% (Job Zone 5), respectively
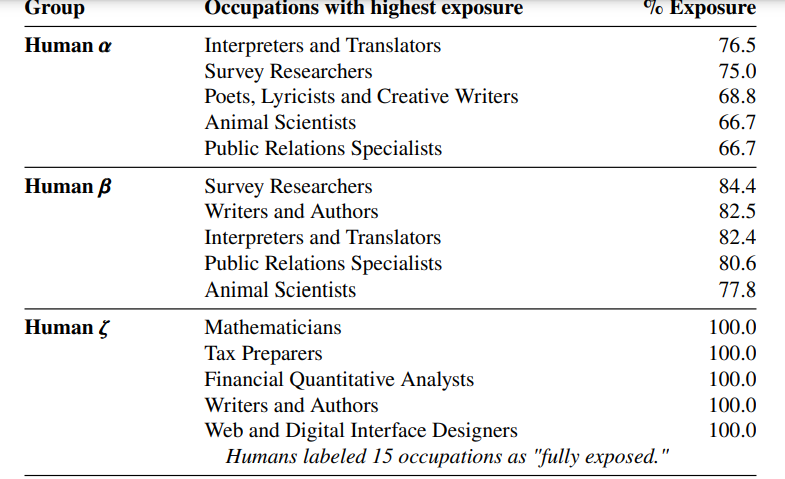
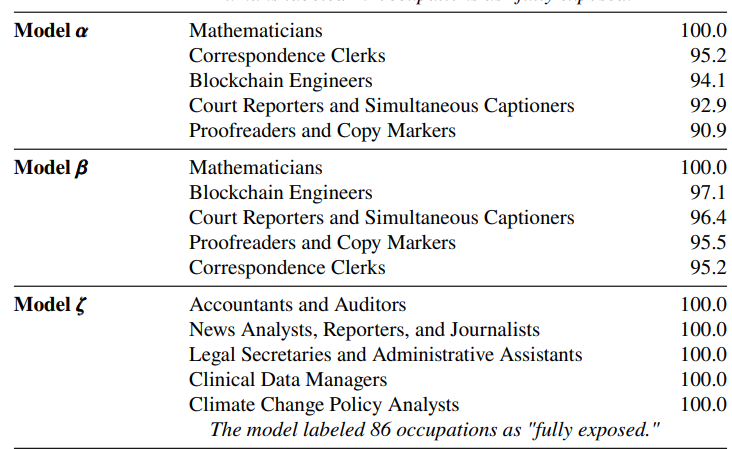

Table 4: Occupations with the highest exposure according to each measurement. The final row lists the occupations with the highest 𝜎 2 value, indicating that they had the most variability in exposure scores. Exposure percentages indicate the share of an occupation’s task that are exposed to GPTs (𝛼) or GPT-powered software (𝛽 and 𝜁 ), where exposure is defined as driving a reduction in time it takes to complete the task by at least 50% (see exposure rubric A.1). As such, occupations listed in this table are those where we estimate that GPTs and GPT-powered software are able to save workers a significant amount of time completing a large share of their tasks, but it does not necessarily suggest that their tasks can be fully automated by these technologies
6 Discussion (excerpt)
6.1 GPTs as a General-Purpose Technology
Earlier in this paper we discuss the possibility that GPTs could be classified as a general-purpose technology.
This classification requires GPTs to meet three core criteria: improvement over time, pervasiveness throughout the economy, and the ability to spawn complementary innovations (Lipsey et al., 2005).
Evidence from the AI and machine learning literature thoroughly demonstrates that GPTs meet the first criteria — they are improving in capabilities over time with the ability to complete or be helpful for an increasingly complex set of tasks and use-cases (see 2.1).
This paper presents evidence to support the latter two criteria, finding that GPTs on their own can have pervasive impacts across the economy, and that complementary innovations enabled by GPTs — particularly via software and digital tools — can have widespread application to economic activity Figure 3 offers one illustration of the potential economic impact of complementary software built on top of GPTs.
Taking the difference in the y-axis (the share of all occupations) between 𝛼 and 𝜁 at a given point along the x-axis (the share of tasks within an occupation that are exposed) gives the aggregate within-occupation exposure potential attributable to tools and software over and above direct exposure from GPTs on their own.
The difference in means across all tasks between 𝛼 and 𝜁 of 0.42 using the GPT-4 annotations and 0.32 using the human annotations (see Figure 3), suggests that the average impact of GPT-powered software on task-exposure may be more than twice as large as the mean exposure from GPTs on their own (mean 𝜁 of 0.14 based on both human annotations and GPT-4 annotations).
While our findings suggest that out-of-the-box these models are relevant to a meaningful share of workers and tasks, they also suggest that the software innovations they spawn could drive a much broader impact.
One component of the pervasiveness of a technology is its level of adoption by businesses and users.
This paper does not systematically analyze adoption of these models, however, there is early qualitative evidence that adoption and use of GPTs is becoming increasingly widespread.
The power of relatively simple UI improvements on top of GPTs was evident in the rollout of ChatGPT — wherein versions of the underlying language model had been previously available via API, but usage skyrocketed after the release of the ChatGPT interface. (Chow, 2023; OpenAI, 2022) Following this release, a number of commercial surveys indicate that firm and worker adoption of LLMs has increased over the past several months. (Constantz, 2023; ResumeBuilder.com, 2023) Widespread adoption of these models requires addressing existing bottlenecks. A key determinant of their utility is the level of confidence humans place in them and how humans adapt their habits. For instance, in the legal profession, the models’ usefulness depends on whether legal professionals can trust model outputs without verifying original documents or conducting independent research. The cost and flexibility of the technology, worker and firm preferences, and incentives also significantly influence the adoption of tools built on top of LLMs. In this way, adoption may be driven by progress on some of the ethical and safety risks associated with LLMs: bias, fabrication of facts, and misalignment, to name a few OpenAI (2023a). Moreover, the adoption of LLMs will vary across different economic sectors due to factors such as data availability, regulatory environment, and the distribution of power and interests. Consequently, a comprehensive understanding of the adoption and use of GPTs by workers and firms requires a more in-depth exploration of these intricacies. One possibility is that time savings and seamless application will hold greater importance than quality improvement for the majority of tasks. Another is that the initial focus will be on augmentation, followed by automation (Huang and Rust, 2018). One way this might take shape is through an augmentation phase where jobs first become more precarious (e.g., writers becoming freelancers) before transitioning to full automation.
6.2 Implications for US Public Policy
The introduction of automation technologies, including LLMs, has previously been linked to heightened economic disparity and labor disruption, which may give rise to adverse downstream effects (Acemoglu and Restrepo, 2022a; Acemoglu, 2002; Moll et al., 2021; Klinova and Korinek, 2021; Weidinger et al., 2021, 2022).
Our results examining worker exposure in the United States underscore the need for societal and policy preparedness to the potential economic disruption posed by LLMs and the complementary technologies that they spawn.
Our results examining worker exposure in the United States underscore the need for societal and policy preparedness to the potential economic disruption posed by LLMs and the complementary technologies that they spawn
While it is outside the scope of this paper to recommend specific policy prescriptions to smooth the transition to an economy with increasingly widespread LLM adoption, prior work such as (Autor et al., 2022b) has articulated several important directions for US policy related to education, worker training, reforms to safety net programs, and more.
6.3 Limitations and Future Work
In addition to those discussed above, we highlight some particular limitations of this work that warrant further investigation. Primarily, our focus on the United States restricts the generalizability of our findings to other nations where the adoption and impact of generative models may differ due to factors such as industrial organization, technological infrastructure, regulatory frameworks, linguistic diversity, and cultural contexts. We hope to address this limitation by extending the study’s scope and by sharing our methods so other researchers can build on them. Subsequent research efforts should consider two additional studies: one exploring GPT adoption patterns across various sectors and occupations, and another scrutinizing the actual capabilities and limitations of state-of-the-art models in relation to worker activities beyond the scope of our exposure scores. For example, despite recent advances in multimodal capabilities with GPT-4, we did not consider vision capabilities in the 𝛼 ratings on direct GPT-exposure (OpenAI, 2023b). Future work should consider the impact of such capability advances as they unfold. Furthermore, we acknowledge that there may be discrepancies between theoretical and practical performance, particularly in complex, open-ended, and domain-specific tasks.
7 Conclusion [excerpt]
In conclusion, this study offers an examination of the potential impact of LLMs, specifically GPTs, on various occupations and industries within the U.S. economy.
By applying a new rubric for understanding LLM capabilities and their potential effects on jobs, we have observed that most occupations exhibit some degree of exposure to GPTs, with higher-wage occupations generally presenting more tasks with high exposure.
Our analysis indicates that approximately 19% of jobs have at least 50% of their tasks exposed to GPTs when considering both current model capabilities and anticipated GPT-powered software.
Our analysis indicates that approximately 19% of jobs have at least 50% of their tasks exposed to GPTs when considering both current model capabilities and anticipated GPT-powered software.
Our research aims to highlight the general-purpose potential of GPTs and their possible implications for US workers.
Previous literature demonstrates the impressive improvements of GPTs to date (see 2.1). Our findings confirm the hypothesis that these technologies can have pervasive impacts across a wide swath of occupations in the US, and that additional advancements supported by GPTs, mainly through software and digital tools, can have significant effects on a range of economic activities. However, while the technical capacity for GPTs to make human labor more efficient appears evident, it is important to recognize that social, economic, regulatory, and other factors will influence actual labor productivity outcomes. As capabilities continue to evolve, the impact of GPTs on the economy will likely persist and increase, posing challenges for policymakers in predicting and regulating their trajectory.
Further research is necessary to explore the broader implications of GPT advancements, including their potential to augment or displace human labor, their impact on job quality, impacts on inequality, skill development, and numerous other outcomes.
By seeking to understand the capabilities and potential effects of GPTs on the workforce, policymakers and stakeholders can make more informed decisions to navigate the complex landscape of AI and its role in shaping the future of work.
7.1 GPT Conclusion (GPT-4’s Version)
Generative Pre-trained Transformers (GPTs) generate profound transformations, garnering potential technological growth, permeating tasks, greatly impacting professions.
This study probes GPTs’ potential trajectories, presenting a groundbreaking rubric to gauge tasks’ GPT exposure, particularly in the U.S. labor market.
7.2 GPT Conclusion (Author-Augmented Version)
Generative Pre-trained Transformers (GPTs) generate profound transformations, garnering potential technological growth, permeating tasks, gutting professional management. Gauging possible trajectories?
Generate pioneering taxonomies, gather policymakers together, generalize past today
Acknowledgments
Thank you to the group of annotators who helped us annotate task exposure, including Muhammad Ahmed Saeed, Bongane Zitha, Merve Özen Şenen, J.J., and Peter Hoeschele. We also thank Lauryn Fuld, Ashley Glat, Michael Lampe, and Julia Susser for excellent research assistance. We thank Miles Brundage for significant feedback on this paper. We thank Todor Markov and Vik Goel for setting up the infrastructure we use to run our rubrics with GPT-4. We thank Lama Ahmad, Donald Bakong, Seth Benzell, Erik Brynjolfsson, Parfait Eloundou-Enyegue, Carl Frey, Sarah Giroux, Gillian Hadfield, Johannes Heidecke, Alan Hickey, Eric Horvitz, Shengli Hu, Ashyana Kachra, Christina Kim, Katya Klinova, Daniel Kokotajlo, Gretchen Krueger, Michael Lampe, Aalok Mehta, Larissa Schiavo, Daniel Selsam, Sarah Shoker, Prasanna Tambe, and Jeff Wu for feedback and edits at various stages of the project.
LLM assistance statement
GPT-4 and ChatGPT were used for writing, coding, and formatting assistance in this project.
Originally published at https://arxiv.org
About the authors & affiliations
- Tyna Eloundou 1 ,
- Sam Manning 1,2,
- Pamela Mishkin ∗1 , and
- Daniel Rock 3
1OpenAI
2OpenResearch
3University of Pennsylvania







