



The Health Strategist
research and strategy institute
for continuous transformation,
for in person health and digital health
Joaquim Cardoso MSc
Chief Research and Strategy Officer (CRSO)
May 9, 2023
ONE PAGE SUMMARY
Once leaders identify their golden use cases, they will need to work with their technology teams to make strategic choices about whether to fine-tune existing LLMs or to train a custom model.
1.Fine-Tuning an Existing Model.
- Adapting existing open-source or paid models is cost effective — in a 2022 experiment, Snorkel AI found that it cost between $1,915 and $7,418 to fine-tune a LLM model to complete a complex legal classification.
- Such an application could save hours of a lawyer’s time, which can cost up to $500 per hour.
Fine-tuning can also jumpstart experimentation, whereas using in-house capabilities will siphon off time, talent, and investment. And it will prepare companies for the future, when generative AI is likely to evolve into a model like cloud services:
a company purchases the solution with the expectation of achieving quality at scale from the cloud provider’s standardization and reliability.
But there are downsides to this approach.
Such models are completely dependent on the functionality and domain knowledge of the core model’s training data; they are also restricted to available modalities, which today are comprised mostly of language models.
And they offer limited options for protecting proprietary data — for example, fine-tuning LLMs that are stored fully on premises.
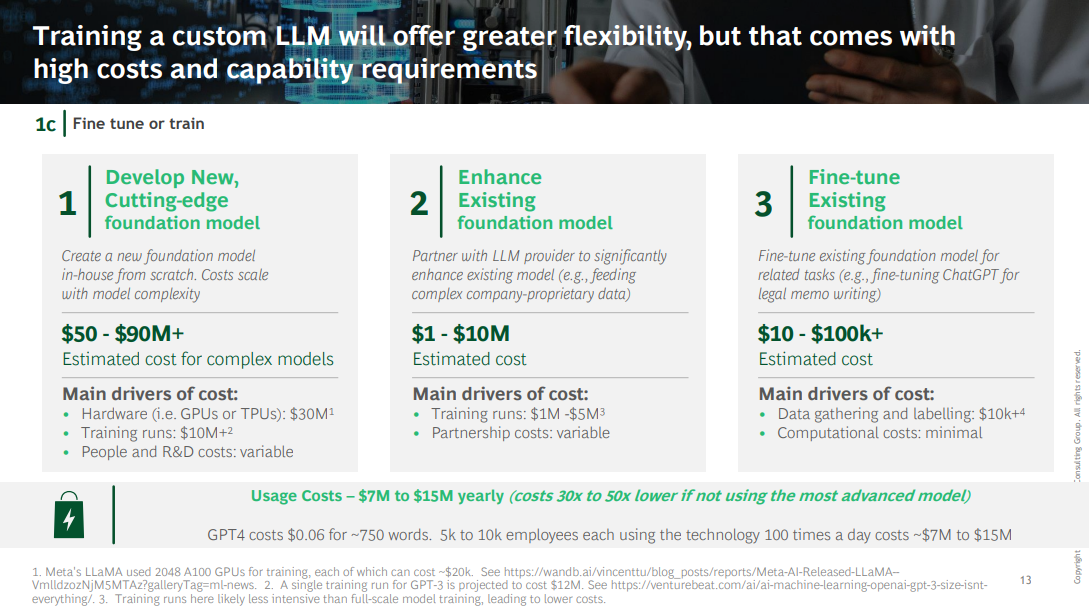
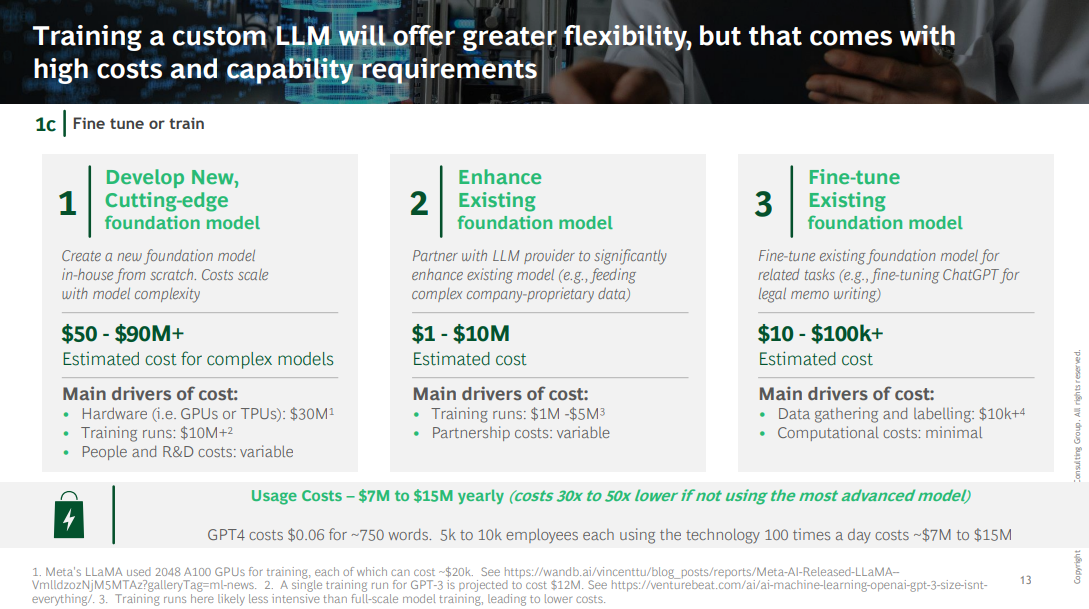
2.Training a New or Existing Model.
Training a custom LLM will offer greater flexibility, but it comes with high costs and capability requirements:
- an estimated $1.6 million to train a 1.5-billion-parameter model with two configurations and 10 runs per configuration, according to AI21 Labs.
- To put this investment in context, AI21 Labs estimated that Google spent approximately $10 million for training BERT …
- … and OpenAI spent $12 million on a single training run for GPT-3.2 (Note that it takes multiple rounds of training for a successful LLM.)
These costs — as well as data center, computing, and talent requirements — are significantly higher than those associated with other AI models, even when managed through a partnership.
The bar to justify this investment is high, but for a truly differentiated use case, the value generated from the model could offset the cost.

Plan Your Investment
Leaders will need to carefully assess the timing of such an investment, weighing the potential costs of moving too soon on a complex project for which the talent and technology aren’t yet ready against the risks of falling behind.
Today’s generative AI is still limited by its propensity for error and should primarily be implemented for use cases with a high tolerance for variability.
CEOs will also need to consider new funding mechanisms for data and infrastructure — whether, for example, the budget should come from IT, R&D, or another source — if they determine that custom development is a critical and time-sensitive need.
The “fine-tune versus train” debate has other implications when it comes to long-term competitive advantage.
Previously, most research on generative AI was public and models were provided through open-source channels.
Because this research is now moving behind closed doors, open-source models are already falling far behind state-of-the-art solutions.
In other words, we’re on the brink of a generative AI arms race.
Source: Adapted from BCG
This is an excerpt from the paper “The CEO’s Guide to the Generative AI Revolution MARCH 07, 2023 By François Candelon, Abhishek Gupta, Lisa Krayer, and Leonid Zhukov”







