




the health strategist
institute for strategic health transformation
& digital technology
Joaquim Cardoso MSc.
Chief Research and Strategy Officer (CRSO),
Chief Editor and Senior Advisor
October 17, 2023
One page summary
What is the message?
The digital transformation of the UK National Health Service (NHS) has created a vast landscape of patient data, enabling a wide range of secondary uses, but raising concerns regarding privacy, transparency, and the need for secure data environments.
This study explores the complex NHS data ecosystem, highlights the diversity of data users, and underscores the importance of restructuring and investment to ensure security and value for patients and healthcare provider.

Key Takeaways
Data Abundance and Diversity:
The NHS’s digital transformation has resulted in extensive electronic health records, containing detailed patient data, which is being utilized for various secondary purposes.
Decentralization Challenges:
Decentralization of data management and technology procurement, along with the absence of a national data infrastructure, have created a complex and fragmented data landscape.
Privacy and Transparency Concerns:
Privacy and transparency risks have been highlighted, emphasizing the need for secure population data resources, as well as patient and citizen engagement.
Digital Transformation Ambitions:
The UK government aims to harness data for personalized health interventions, artificial intelligence predictions, and advancements in pharmaceuticals and life sciences, aligning with international digital transformation trends.
Investment for Balance:
To achieve value from this data, investment should focus on enhancing data analysis capabilities while maintaining a balance between privacy and transparency.
Complex Data Flows:
The study maps electronic data flows originating from NHS England, detailing various data extractors, data consumers, and their interconnections.
Distribution of Data:
Primary care data is widely distributed, and data extraction volume varies across different data types and providers. However, there is substantial duplication between databases.
Consent and Reporting:
Data extraction relies on alternative legal provisions, and patient control is primarily achieved through opt-out mechanisms.
Secure Data Environments:
The study highlights the concept of secure data environments (SDEs), where data can be safely analyzed. While NHS Digital provides a significant volume of linked data, many consumers prefer data transfer outside SDEs.
Statistics and Figures
- Over 95% of data consumers indirectly collect data via data extractor intermediaries.
- There are at least 460 non-NHS organizations using NHS data for various purposes.
- Eight top consumers of NHS data include researchers from 216 universities or academic organizations, 143 pharmaceutical and life sciences companies, and 44 non-profit organizations.
- Prospective cohorts, local centers, and one commercial data extractor are involved in linking multimodal imaging or genomics data.
- Patient consent for data usage is relatively low, with opt-out mechanisms playing a significant role.
- NHS Digital provides whole-population data for COVID-19 analyses but most consumers opt for data transfer outside SDEs.
- The interactive DataInsights website presents detailed visualizations for better understanding of the complex NHS data landscape.
Conclusion
This study reveals that patient data dissemination in NHS-led projects has outstripped public awareness, highlighting the need for restructuring and investment to ensure security, diversity, and value return.
Administrative regions responsible for commissioning play a pivotal role, and public spending should prioritize foundational components rather than duplicative infrastructure.
Addressing bottlenecks in infrastructure use, public assent, data extraction technologies, multimodality, and value return models is essential for a successful data transformation within the NHS.
DEEP DIVE

Mapping and evaluating national data flows: transparency, privacy, and guiding infrastructural transformation [excerpt]
The Lancet
Joe Zhang, BMBCh; Jess Morley, MS; Jack Gallifant, MSc; Chris Oddy, MBBS; Prof James T Teo, PhD; Prof Hutan Ashrafian, PhD; Prof Brendan Delaney, PhD; Prof Ara Darzi, PhD
October, 2023
Summary
The importance of big health data is recognised worldwide. Most UK National Health Service (NHS) care interactions are recorded in electronic health records, resulting in an unmatched potential for population-level datasets. However, policy reviews have highlighted challenges from a complex data-sharing landscape relating to transparency, privacy, and analysis capabilities. In response, we used public information sources to map all electronic patient data flows across England, from providers to more than 460 subsequent academic, commercial, and public data consumers. Although NHS data support a global research ecosystem, we found that multistage data flow chains limit transparency and risk public trust, most data interactions do not fulfil recommended best practices for safe data access, and existing infrastructure produces aggregation of duplicate data assets, thus limiting diversity of data and added value to end users. We provide recommendations to support data infrastructure transformation and have produced a website (https://DataInsights.uk) to promote transparency and showcase NHS data assets.
Introduction
Digital transformation in the UK National Health Service (NHS) has resulted in most present and historical patient interactions being stored within electronic health record systems.
A focus on interoperability has enabled widespread data sharing between discrete systems, making medical records available for direct care, but also enabling aggregation of large datasets for secondary uses. As a result, data within NHS systems are a valuable resource, containing detailed longitudinal data of a large and diverse population. Although the NHS conducts central administrative data collection, data-sharing infrastructure has also evolved through local initiatives, resulting in a patchwork landscape of data extractions without determining what databases or data users exist. This situation has occurred because of three processes. First, following early failures in central information technology programmes, responsibility for technology procurement was delegated to local providers and commissioners. Second, attempts to create national data infrastructure for secondary uses have not achieved public assent, resulting in capability gaps that are increasingly filled by third parties.
Third, data controller responsibility in NHS England falls to nearly 7000 individual providers who make independent decisions on how data could be used.
Overall, decentralisation has allowed procurement to directly support local population needs. However, as discussed in the five year forward view and government reviews, being unable to reach a compromise between over-centralisation and letting a thousand flowers bloom through fragmented local delivery has prevented effective use of unified population data for improving clinical outcomes and reducing health inequalities.
Inadequate consistency in data controller decision-making processes could also expose patients to risk from privacy breaches, as illustrated by identifiable data exposure to Meta (Facebook) by individual NHS Trusts.
Policy reviews have highlighted privacy and transparency risks in a complex landscape and a need for developing secure population data resources.
At the same time, government strategy aims to secure capabilities such as personalised health intervention, artificial intelligence prediction, and pharmaceutical and life sciences development—all at a population scale.
These ambitions share much in common with other countries undergoing digital transformationmand are supported by the most extensive package of data infrastructure investment in NHS England history, with up to £200 million announced to support development of secure data environments (SDEs), and a further £480 million for a national federated data platform.
To achieve value, investment must increase data analysis capabilities while striking a balance between privacy and transparency concerns. Policy objectives (panel) should, therefore, be supported by low-level assessment of the current landscape and by assent from an adequately informed public. In this study, we map and characterise all electronic data flows originating from NHS England primary and secondary care providers, flowing to and between visible data consumers. We present three aims: (1) to follow recommendations in the NHS strategy review by Goldacre and Morley for mapping bulk data flows, thus enabling the understanding of privacy risks, capabilities, and positioning of secure data environments; (2) to transparently summarise the complex NHS data landscape; and (3) to build on existing registries of NHS data assets, such as those maintained by Health Data Research UK (HDR UK), but with focus on comprehensiveness, data provenance, and data usage for each asset, through use of systematic mapping techniques. On the basis of our findings, we provide general recommendations to support national data transformation. Finally, we present an interactive public-facing dashboard to visualise data use and to assist with discovery of NHS real-world data assets by the global research community.
Summary of relevant UK health data strategy recommendations 2021–22, and relevant questions for landscape mapping, which aim to discover specific details pertinent to strategic recommendations and are used to construct descriptive typology domains
Public trust in the use of health data
Recommendations
- Improve transparency and encourage patient and citizen engagement12, 13, 19, 20
- Move to analytics within controlled, secure data environments12, 13, 19, 20
- Reconsider governance models and approach to de-identified data13, 21
Questions posed
- What data are extracted, who is using it, and for what purposes; how transparent are data extractions and usage?
- Where are secure environments for patient data, and how much data is provisioned securely?
- What control do patients have over consented and non-consented use of de-identified data?
Infrastructural transformation
Recommendations
- Data should be a centralised National Health Service capability, and data flows should be discovered, mapped, and rationalised12, 20
- New infrastructural solutions to investigate and reduce data and digital inequalities, and avoid digital exclusion13, 20
Questions posed
- How do content, volume, and distribution of NHS-controlled data flows compare to non-NHS data flows?
- How equitable are existing data extractions by location, extractor, and data content?
Future data-driven capabilities
Recommendations
- Develop multimodal data including genomics to empower researchers and personalised medicine13, 22
- New guidance and infrastructure to support safe commercial collaboration with life sciences, health technology, and pharmaceutical sectors12, 13, 23
- Support clinical decision makers at every level, and take advantage of artificial intelligence technologies13, 23, 24
Questions posed
- How prevalent are multimodal data linkages?
- How do commercial users access or receive data?
- How does secondary use of data inform clinical care through population health and algorithmic tools?
Methods
Data flows and inclusion and exclusion criteria
We consider the electronic provision of patient-level structured, coded records from NHS England providers for non-direct care uses, which represents data from routine health-care capture but excludes unstructured text records. We term provision of data from one organisation to another as data flow. We include data flows that originate in primary or secondary care providers, which might pass to, and between, subsequent public, academic, non-profit, or commercial entities. Entities might directly procure data from provider health records (ie, data extractor), maintain a standing collection of data for secondary use (ie, database), or use data for a specified purpose (ie, data consumers).
As a snapshot of current infrastructure, we included only systematised data flows or single instance flows between April, 2021, and April, 2022. We excluded entities that collect data by manual collection, as these are not a function of interoperable data infrastructure. We also excluded entities that only provide extraction software, storage, or backup services (eg, cloud providers). Multimodal data, including imaging and genomic data, were considered in the context of linkage to electronic health record data.
Information extraction
There are no unified registers of patient data extraction, sublicensing, or usage in NHS England.
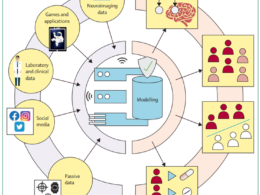
Figure 1 shows our approach to information discovery. Altogether, we reviewed nine categories of information source, including legal documents produced in respect of the General Data Protection Regulation (GDPR), administrative data use registers, and academic metadata registers. Additional information was requested from 216 secondary care trusts and 106 clinical commissioning groups with freedom of information requests, regarding shared care record data flows and secondary uses. We did scoping reviews of the MEDLINE database to discover named NHS databases, and their subsequent usage in observational research.

We collected characteristics of each data flow, such as data origin and destination, data content and volume, method of data provision or access by consumer, information governance provisions including consent and opt-out mechanisms, how data usage is reported, and how data are used by the destination entity. Information discovery was done between April, 2022, and November, 2022 (JZ, JG, and CO) and is reported in the appendix (p 2).
Reporting, typology, and visualisation
To guide synthesis and narrative reporting of our findings, we summarised themes and recommendations from NHS data strategy publications from 2021 to 2022 (panel). To enable easier description and comparison between data extractors, we created a descriptive typology across important domains.
These domains were constructed with relevance to the themes in the panel, while prioritising ease of interpretation by non-experts. Domains include organisation type, data content, data volume and scope, data linkages, method of data provision to consumer, degree of public-facing transparency, model of consent, and onwards consumers and use cases.
We showed discovered information as a graph, with entities as nodes and data flows as relationships. Visualisations (including online dashboards) were created with Python 3.7, Gephi 0.1, and Tableau version 2022.2. To minimise risk of reidentification (ie, connecting small datasets with specific providers), individual care providers and regional bodies are kept anonymous.
Results
Data flows, extractions, and consumers
National data flows are shown in figure 2. Across NHS England, 216 hospital trusts and 6544 primary care providers record health-care interactions for a population of 56 million. All onward data flows originate from four models of data extraction, which are: (1) extraction of structured clinical codes from primary care electronic health records; (2) administrative data collection by NHS Digital from secondary care, including main diagnoses for individual care episodes; (3) data aggregated within regional shared care record data warehouses, representing capture of standardised messages from primary and secondary care electronic health records; and (4) proprietary secondary care data pipelines, generally extracting data of higher temporal and information resolution when compared with administrative datasets.
Extracted data feed a vast ecosystem of secondary uses, which include at least 460 non-NHS organisations who have accessed, maintained, or used NHS data since April, 2021. At the far end of the data flow chains, consumers include researchers from 216 universities or academic organisations; 143 pharmaceutical, life sciences, data analytics, and consulting companies; and 44 non-profit organisations. Figure 3 shows the top consumers and main use cases in each category.

More than 95% of consumers collect these data indirectly via data extractor intermediaries (eg, NHS Digital, regional NHS bodies, and 37 non-NHS organisations). Although the median data flow chain consists of three entities (ie, provider, extractor, and consumer), we discovered 56 (12%) of 460 consumers sharing data with at least one further consumer.
Types of data extractor
Data extractors are key intermediary nodes that maintain and provide datasets to consumers. We describe eight distinct extractor types (figure 4), and individual extractors are described in the appendix (p 5).

NHS Digital hosts the only whole-population secondary care datasets, derived from administrative collections, and maintains the General Practice Extraction Service Data for Pandemic Planning and Research (GDPPR) from primary care extractions for COVID-19 use. Other data of national scope is held by primary care research databases, which extract from differing numbers of practices across the country, with the largest, the Clinical Practice Research Datalink, supporting 18 million active patients. commercial data extractors can act as brokers (ie, licensing datasets to consumers), including databases run by companies such as IQVIA and cegedim, but can also provide specific services to customers. Agreements are maintained with individual providers.
We found 24 active shared care records systems that hold data for direct-care purposes. System suppliers might offer additional population health analytics capabilities. By the end of 2023, many systems will be centralised into local health and care record regions, with catchments of up to 10 million patients. A subset of these systems enable access to hosted data for research purposes.
The NHS is administered through 42 integrated care systems that use linked data for commissioning and population health uses, supported by commissioning support units and analytics companies. These data extractions have population coverage for each geographical region. Some datasets are also made available for academic users. Smaller volume secondary care data pipelines support seven academic research collaboratives (eg, the Health Informatics Collaborative), which curate cohort data on the basis of thematic inclusion criteria, and 12 secondary care centre databases accessible to research users. Finally, two prospective cohorts (ie, the UK Biobank and Genomics England) perform linkage of genomics data to primary care and NHS Digital secondary care data to enrich cohort follow-up.
Balance of data assets and distribution
Data extractors differ by type and volume of maintained data, and act as flow multipliers, by each enabling multiple distribution routes. This results in differing availability and usage of different data types (figure 5). The most prevalent maintained data are from primary care. Whole-population primary care data are available only for COVID-19 research via GDPPR, or the federated analytics platform OpenSAFELY. Other data, held in commercial and academic databases of national scope (n=7), are extracted for a cumulative, overlapping, active population of 76 million patients, but with a median independent database size of 13 million (IQR 11–15 million) active patients. Of data extractions that were reported by primary care practices, 28% report extraction by two databases and 21% reported data extractions by three or more, suggesting substantial duplication between databases.

Administrative secondary care data are the only general use whole-population data asset that is held by NHS Digital. Partial copies are permanently maintained in at least 12 additional research databases and in regional care systems. Overall, primary care and administrative secondary care data were distributed to 90% of unique consumers in the study period.
Conversely, we estimate the median extraction size from hospital data pipelines to be less than half a million patient episodes. Other more granular secondary care data are found in shared care record data warehouses, but only four shared care record databases support secondary use for research, including two for COVID-19 usage only (total 3·5 million patients).
Linkage to multimodal imaging or genomics data is found exclusively at prospective cohorts, local centres, and one commercial data extractor (23andMe).
The largest multimodal cohort includes half a million patients in the UK Biobank, linking genomic data to primary and administrative secondary care data, and is the single most influential data distributor, supplying 190 different consumers.
Consent and reporting transparency
Within discovered extractors, only two prospective cohort databases and one commercial genomics database extract and distribute patient data with explicit consent, accounting for less than 0·5% of maintained data assets. NHS Digital facilitates consented linkage to external research cohorts. Most extractions occur under alternative legal provisions for performing tasks in the public interest.
Patient control over data use relies on opt-out mechanisms, at the levels of primary care extraction, primary care provision to shared care records, and through a central record held on the NHS spine.
Care providers are expected to report possible uses of patient data across primary care practice websites. Reporting of data extractions through primary care practice websites (n=6544) was estimated at 63% of what would be expected from reports of practice enrolment by databases. Secondary care providers report potential for data to be used in research, but with no specificity to projects or consumers. For data extractors, NHS Digital, primary care research databases, and prospective cohort studies provide public facing registers of active projects. Most commercial data extractors provide only non-specific description of onwards data usage.
Secure data environments
Although dedicated research platforms with secure access to patient data are traditionally known as trusted research environments, the NHS now considers all privacy-focused data analysis environments under the term SDE.
The greatest volume of linked data can be accessed in an NHS Digital internal environment, including whole-population data for COVID-19 analyses. However, 102 (78%) of 130 NHS Digital data consumers, including 31 (89%) of 35 companies, opted for data to be transferred outside of an SDE. We discovered 20 additional environments (figure 5) that otherwise fulfilled SDE criteria, accounting for data provision to 35% of unique consumers.
Public-facing dashboard
We present interactive visualisations online on the DataInsights website. The website is structured across three infographics written for non-experts, including an explainer of different data types, flows, provenance, and destinations; a comprehensive description of systematically discovered electronic health record databases that are accessible to external researchers; and a cross-section of the largest users of NHS data. Where included, more detailed metadata, including covariable information, can be discovered through the HDR UK gateway.
Risks to public trust in data use
We have described a complex landscape that contains hundreds of organisations positioned along multistage data flow chains. The use of de-identified data without explicit consent is a point of controversy within post-pandemic and historical failures of NHS data programmes. The current landscape shows failures in transparency and privacy that risk compromising public trust.
Data usage most often occurs two or three interactions down a chain. At each stage, data flows have a one-to-many relationship. For any patient in NHS England, data flows to a minimum of two and up to 16 potential data extractors, each with their own ecosystem of subsequent data flows. These stages of multiplicative data distribution place patients at considerable distance from data usage. Furthermore, we found reporting of data uses to be incomplete or having low specificity, including boilerplate notices that state data are used for research, which risks violation of the no surprises principle within data protection legislation, and places the onus on patients to actively investigate how their data is being used.
The majority of the UK public support the use of de-identified data for public benefit or to advance medical knowledge but are more cautious about use of data for commercial profit, reflecting a similar stance to populations worldwide.
Public research and dialogue, including that commissioned by the National Data Guardian, find assent to be predicated on full transparency, requiring clear distinction between specific use cases.
Data ultimately reflect individuals, and when transparency is low, patients are unable to understand what inferences might be drawn from their digital data, thus undermining autonomy and trust.
Public assent is important in the context of de-identified data. Data flows in this study are either anonymised through personal identifiable data removal or pseudonymised with keys for reidentification or linkage. In either case, reidentification through temporal characteristics of events or isolated rare conditions are a recognised risk.
Clarity over risk mitigation is especially important if patients have little control or statutory protection over how data are used. The Goldacre review establishes potential risks in unaudited bulk data flows and produces strong recommendations for restructuring data into a small number of secure environments.
We found physical data transfers outside of SDEs to be the majority occurrence. In data flows and usage that are audited, previous investigative research has uncovered numerous breaches of data contracts and confidentiality agreements, including in 33 (100%) audited organisations who used NHS Digital data over the same period as this study.
Breaches are also likely to occur if data flows are unaudited, which is a majority of the landscape. The possibility of unobserved data breaches risks additional damage to patient trust. In addition, although the risk of patient reidentification by a malicious individual or group is low, this risk is magnified if numerous data breaches are occurring across hundreds of data flow chains.
In consideration of persistent risks, the Goldacre review further recommends a category of de-identified but re-identifiable data.
New guidance from the Information Commissioner’s Office proposes factors for testing risk of reidentification, but these conditions are open to interpretation. In the USA, the Health Insurance Portability and Accountability Act, like the GDPR, does not apply to de-identified data; however, there is more structured focus on delineating technical de-identification best practices, alongside expert peer review to explore reidentification risks, which could produce greater uniformity in practice and increase confidence in anonymisation.
Robust opt-out mechanisms can help to maintain trust in de-identified data use. However, positioning of opt-outs has three potential risks. First, although there are clear differences in public assent for different uses of data, these uses are not considered by blanket opt-outs positioned at extraction level. Second, data flow to shared care records might be controlled by an opt-out of information exchange for direct care, potentially asking patients to choose between having data shared for both clinical care and secondary uses, or not having data shared at all. Third, even if a patient opts out at all levels, de-identified data could still flow to numerous secondary uses.
Data volume hides insufficient diversity in information and population
Our findings lend broad support to expansion of SDEs. However, investment must consider necessity for additional nodes of data aggregation, linkage, and provision. At face value, the NHS possesses enormous data resources, but these resources partly reflect duplication, rather than information or population diversity.
Enormous quantities of primary care data are segmented across numerous databases. Similarly, databases hold partial, duplicated NHS Digital datasets in different locations for onward provision. Present NHS Digital infrastructure and the federated OpenSAFELY platform are technologically capable of supporting secure provision of whole-population linked data as a general research asset (ie, a capability shared by only a handful of countries with much smaller populations), but only for COVID-19 uses. Limitations in national capability, therefore, reflect public concerns regarding risk, rather than availability of data infrastructure. Conversely, we find technological gaps in access to secondary care electronic health record data, in which multiplicity of vendor systems makes interoperability a continued challenge, with high barriers of entry limiting success to a few digitally mature centres.
This imbalanced landscape has implications for effective and equitable data use. Insufficient information diversity affects research capabilities, as individual data sources are known to suffer from quality issues and missing data.
Complementary linked data types enable complete capture of patient lifetime journeys and ensure that NHS services meet the needs of everyone in the population. In particular, the need for high-quality secondary care data was exemplified during the COVID-19 pandemic, when in-hospital trajectories were crucial for informing research and planning.
Reduced population diversity risks negative bias resulting from differences between high and low data flow density areas. Data flows are determined by local data-sharing practices, by presence of digitally mature academic centres, and recruiting practices for cohort studies.
These upstream factors are known to result in unrepresentative data that adversely affect research, pharmaceutical evaluation, and artificial intelligence development.
Routinely collected NHS data have particular value due to universal health-care access, especially compared with insurance-based systems, in which data aggregation largely represents well-served populations.
These priorities are reflected in national strategy aiming to reduce data and digital disparities.
Overall, new SDEs will enable further nodes of access to data that are already widely available but might not widen information or population diversity. Work is required in data extraction technologies and in expanding multimodal resources that support personalised medicine interventions. One possible route for improving secondary care electronic health record data availability is through existing shared care records, which have developed separately from research infrastructure. However, legal and governance provisions for shared care records might not consider data consumption for secondary uses. For multimodal data, high profile genomics projects such as Our Future Health and the expansion of radiomics programmes, such as the National COVID-19 Chest Imaging Database,
are key to addressing data imbalance. For now, the best way to use available resources might be through patient and public programmes to achieve assent for expanding available SDEs that already contain linked whole-population data.
Value implications across data flow chains
Data flow mapping allows examination of value gain and loss across each chain. Although a quantitative analysis is outside the scope of this study, several findings warrant additional discussion. Data flow chains carry substantial monetary value, which are multiplicative at each stage through sublicensing fees and commercial consumption. For the largest databases, costs are ultimately borne by researchers or companies that wish to access data, which is described as prohibitive for many in academia
These costs cover infrastructure and administration, but could also produce net income, particularly for commercial brokers. For consumers, data access might additionally support revenue-generating services.
By contrast, value return to patients, care providers, and the NHS is a minority proportion of this landscape.
Some databases offer financial incentive packages for providers (eg, The Health Improvement Network offering either £600 or three iPads for data from 10 000 to 15 000 patients), but these exchanges do not scale to propagation of revenue-generating interactions with consumers.
When considering value for patient care and population health, most data are used for observational research, with public benefits across a long time horizon and real-world impacts that are difficult to quantify. The direct data-driven interventions that are the focus of NHS strategy are seen only in a small number of suppliers of population health and risk stratification services or at the level of regional commissioners. Although a focus on analytics environments is optimal for performing observational research, greater value might be generated through platform infrastructure. Platform infrastructure refers to components that support engineering and maintenance of continuous data flows and tools for entire project lifecycles, including an implementation and delivery stage, beyond that supported by SDE-hosted research.
Finally, we consider value loss. Each database node in a chain requires a substantial monetary cost, which is borne by academic or public funding for research aims. Arguably, a new database that duplicates data already found elsewhere adds little value. Moving research questions into existing SDEs might reduce spending on new and costly data infrastructure, improve collaboration and reproducibility, and reduce the need for bulk physical data transfers. These findings support recommendations in the Goldacre review for avoiding new bulk data aggregations, instead restructuring existing data flows and analyses into a small number of SDEs with advanced capabilities.
Recommendations for data transformation
See the original publication. This is an excerpt version.
Strengths and limitations
See the original publication. This is an excerpt version.
Conclusion
Public reaction to proposed NHS-led data projects suggests an uncomfortable possibility that the extent and methods of patient data dissemination shown in this study far exceed present awareness. Instead, we argue that a process of restructuring is required to ensure security, diversity, and return of value to patients and providers. Administrative regions with responsibility for commissioning are an important node for investment due to existing data flows, public support for population health uses, and proximity to the clinical front line for delivering actionable insights. In general, public spending must deliver more than duplicative analytics infrastructure. Bottlenecks exist in the use of existing infrastructure, public assent, data extraction technologies, multimodality, and models of value return to the NHS. Investment into data transformation must focus on these foundational components.
References
See the original publication. This is an excerpt version.
Originally published at https://www.thelancet.com







00157-7&id=gr2.jpg){kind=link}
00157-7&id=gr1.jpg){kind=link}
00157-7&id=gr3.jpg){kind=link}
00157-7&id=gr4.jpg){kind=link}
00157-7&id=gr5.jpg){kind=link}