




What is the message?
The current landscape of healthcare AI research is characterized by a significant bias in the representation of patient data, with more than half of the datasets used in clinical AI research originating from the U.S. and China.
This lack of diversity poses a substantial challenge to the development and deployment of AI tools, particularly in regions with constrained resources, potentially widening existing care gaps.

EXECUTIVE SUMMARY
What are the key points?
Data Bias and Transferability Issues: Clinical AI tools often fail to perform adequately when deployed in real-world hospital settings due to the problem of transferability. Algorithms trained on datasets from specific patient populations may not generalize well to other demographics, exacerbating disparities in healthcare outcomes.
Global Research Investment Patterns: Despite growing awareness of the importance of diverse patient data, the field of clinical AI research remains skewed towards a few nationalities, primarily the U.S. and China. This imbalance is reflected in both the origin of datasets and the nationality of researchers publishing clinical AI papers.
Implications for Global Healthcare Inequality: The lack of diverse patient data not only affects the performance of AI algorithms but also perpetuates global healthcare inequality. Clinical guidelines and research findings from well-resourced countries may not be applicable or effective in regions with different patient demographics and healthcare systems.
Challenges and Solutions: While addressing data disparities in healthcare AI presents significant challenges, efforts are underway to encourage data collection and pooling of resources in underrepresented countries. Initiatives aimed at fostering collaboration, data sharing, and validation of existing models in diverse settings are crucial steps towards mitigating bias and improving the inclusivity of AI-driven healthcare solutions.
What are the key statistics?
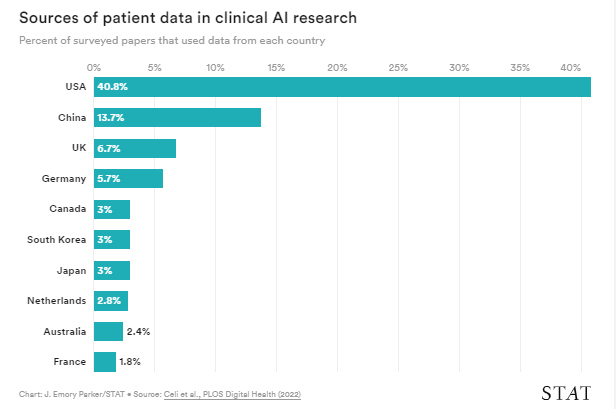
More than half of the datasets used in clinical AI research come from the U.S. and China.
Chinese and American researchers account for over 40% of clinical AI papers published.
172 countries, representing 3.5 billion people, lack public ophthalmic data repositories for research purposes.
Conclusion
The disparity in patient data representation in healthcare AI research is a pressing issue that requires concerted efforts from the global scientific community.
By promoting diversity in datasets, fostering international collaboration, and prioritizing validation in diverse settings, we can ensure that AI-driven healthcare innovations benefit all populations, regardless of geographical location or resource availability.
Infographic
DEEP DIVE
‘We need to be much more diverse’: More than half of data used in health care AI comes from the U.S. and China
Stat
By Katie Palmer
April 6, 2022
As medicine continues to test automated machine learning tools, many hope that low-cost support tools will help narrow care gaps in countries with constrained resources.
But new research suggests it’s those countries that are least represented in the data being used to design and test most clinical AI — potentially making those gaps even wider.
… countries with constrained resources that are least represented in the data being used to design and test most clinical AI — potentially making those gaps even wider.
Researchers have shown that AI tools often fail to perform when used in real-world hospitals.
It’s the problem of transferability: An algorithm trained on one patient population with a particular set of characteristics won’t necessarily work well on another.
Those failures have motivated a growing call for clinical AI to be both trained and validated on diverse patient data, with representation across spectrums of sex, age, race, ethnicity, and more.
Researchers have shown that AI tools often fail to perform when used in real-world hospitals.
It’s the problem of transferability
But the patterns of global research investment mean that even if individual scientists make an effort to represent a range of patients, the field as a whole skews significantly toward just a few nationalities.
But the patterns of global research investment mean that even if individual scientists make an effort to represent a range of patients, the field as a whole skews significantly toward just a few nationalities.
In a review of more than 7,000 clinical AI papers, all published in 2019, researchers revealed more than half of the databases used in the work came from the U.S. and China, and high-income countries represented the majority of the remaining patient datasets.
In a review of more than 7,000 clinical AI papers, all published in 2019, researchers revealed more than half of the databases used in the work came from the U.S. and China ..
“Look, we need to be much more diverse in terms of the datasets we use to create and validate these algorithms,” said Leo Anthony Celi, first author of the paper in PLoS Digital Health (he is also the journal’s editor).
Look, we need to be much more diverse in terms of the datasets we use to create and validate these algorithms
The biggest concern now is that the algorithms that we’re building are only going to benefit the population that’s contributing to the dataset
“The biggest concern now is that the algorithms that we’re building are only going to benefit the population that’s contributing to the dataset. And none of that will have any value to those who carry the biggest burden of disease in this country, or in the world.”
The skew in patient data isn’t unexpected, given Chinese and American dominance in machine learning infrastructure and research.
“To create a dataset you need electronic health records, you need cloud storage, you need computer speed, computer power,” said co-author William Mitchell, a clinical researcher and ophthalmology resident in Australia.
The skew in patient data isn’t unexpected, given Chinese and American dominance in machine learning infrastructure and research.
“To create a dataset you need electronic health records, you need cloud storage, you need computer speed, computer power,”
“So it makes sense that the U.S. and China are the ones that are in effect storing the most data.”
The survey also found Chinese and American researchers accounted for more than 40% of the clinical AI papers, as measured by the inferred nationality of first and last authors; it’s no surprise that researchers gravitate toward the patient data that’s closest — and easiest — to access.
The survey also found Chinese and American researchers accounted for more than 40% of the clinical AI papers
But the risk posed by the global bias in patient representation makes it worth calling out and addressing those ingrained tendencies, the authors argue.
Clinicians know that algorithms can perform differently in neighboring hospitals that serve different patient populations.
They can even lose power over time within the same hospital, as subtle shifts in practice alter the data that flows into a tool.
“Between an institution from São Paulo and an institution in Boston, I think the differences are going to be much, much bigger,” said Celi, who leads the Laboratory of Computational Physiology at MIT. “Potentially, the scale and the magnitude of errors would be greater.”
Clinician guidelines are already tailored to well-resourced countries, and a lack of diverse patient data only stands to widen global health care inequality.
“Most of the research that informs how we practice medicine is performed in a few rich countries, and then there’s an assumption that whatever we learn from these studies and trials performed in a few rich countries will generalize to the rest of the world,” said Celi.
“This is also going to be an issue if we don’t change the trajectory with respect to the creation of artificial intelligence for health care.”
The answer isn’t straightforward, because nations that are resource-poor are also more likely to be data-poor.
The answer isn’t straightforward, because nations that are resource-poor are also more likely to be data-poor.
One popular research target for clinical AI in low-resourced settings is automated screening for eye disease.
Using a portable fundus camera to image the eye, or even a smartphone camera, an algorithm could identify the signs of problems like diabetic retinopathy early enough to intervene.
But as the authors note, 172 countries accounting for 3.5 billion people have no public ophthalmic data repository for researchers to draw from — data deserts that frequently also affect other fields of medicine.
But as the authors note, 172 countries accounting for 3.5 billion people have no public ophthalmic data repository for researchers to draw from — data deserts that frequently also affect other fields of medicine.
That’s why Celi and others are investing in programs to encourage data collection and pooling of machine learning resources in poorly-represented countries.
One consortium is assembling multidisciplinary experts from Mexico, Chile, Argentina, and Brazil to “identify best practices in data diplomacy,” said Celi.
“It turns out the biggest challenge here is really the politics and economics of data,” encouraging those with access to clinical data to open it up for local and international research rather than hoarding it for commercial purposes.
“It turns out the biggest challenge here is really the politics and economics of data,” encouraging those with access to clinical data to open it up for local and international research rather than hoarding it for commercial purposes.
That work can also help double down on efforts to test existing models in areas with data disparities.
If local data collection and curation isn’t possible yet, validation can help ensure that algorithms trained in data-rich countries can, at least, be safely deployed in other settings.
And along the way, those efforts can start to lay the groundwork for long-term data collection, and the ultimate growth of international data repositories.
By quantifying the international bias in AI research, Celi says, “we just don’t end up with ‘things are pretty bad.’”
The group hopes to use this as a baseline against which to measure improvement.
Another recent paper led by Joe Zhang at Imperial College London detailed the creation of a dashboard that tracks the publication of clinical AI research, including the nationality of the first author on each paper.
The first step to solving the problem is measuring it.
Originally published at https://www.statnews.com on April 6, 2022.
Names mentioned
Leo Anthony Celi
William Mitchell, a clinical researcher and ophthalmology resident in Australia.







