This is a republication of the paper “Prediction models for diagnosis and prognosis of covid-19: systematic review and critical appraisal”, published by the BMJ, with the title above. The article is preceded by an Executive Summary by the Editor of the Site.
transformhealth
institute for continuous health transformation
Joaquim Cardoso MSc
Chief Researcher, Editor and Senior Advisor
January 13, 2023
KEY MESSAGE [1]
In healthcare, transitioning from impressive tech demos to deployed AI has been challenging.
- Despite the promise of AI to improve clinical outcomes, reduce costs, and meaningfully improve patient lives, very few models are deployed.
- For example, of the roughly 593 models developed for predicting outcomes among COVID-19 patients, practically none are deployed for use in patient care.
- Deployment efforts are further hampered by the approach of creating and using models in healthcare by relying on custom data pulls, ad hoc training sets, and manual maintenance and monitoring regimes in healthcare IT.
In addition to that, most published prediction model studies developed for Covid-19 outcomes application, were poorly reported and at high risk of bias — such that their reported predictive performances are probably optimistic.
On top of that, the performance of some models with better performance is likely to vary over time and differ between regions, necessitating further validation and potentially updating before implementation.
ABSTRACT OF THE PAPER BELOW:
Prediction models for diagnosis and prognosis of covid-19: systematic review and critical appraisal
Objective
- To review and appraise the validity and usefulness of published and preprint reports of prediction models for prognosis of patients with covid-19, and for detecting people in the general population at increased risk of covid-19 infection or being admitted to hospital or dying with the disease.
Design
- Living systematic review and critical appraisal by the covid-PRECISE (Precise Risk Estimation to optimise covid-19 Care for Infected or Suspected patients in diverse sEttings) group.
Data sources
- PubMed and Embase through Ovid, up to 17 February 2021, supplemented with arXiv, medRxiv, and bioRxiv up to 5 May 2020.
Study selection
- Studies that developed or validated a multivariable covid-19 related prediction model.
Data extraction
- At least two authors independently extracted data using the CHARMS (critical appraisal and data extraction for systematic reviews of prediction modelling studies) checklist; risk of bias was assessed using PROBAST (prediction model risk of bias assessment tool).
Results
- 126 978 titles were screened, and 412 studies describing 731 new prediction models or validations were included.
- Of these 731, 125 were diagnostic models (including 75 based on medical imaging) and the remaining 606 were prognostic models for either identifying those at risk of covid-19 in the general population (13 models) or predicting diverse outcomes in those individuals with confirmed covid-19 (593 models).
- Owing to the widespread availability of diagnostic testing capacity after the summer of 2020, this living review has now focused on the prognostic models.
- Of these, 29 had low risk of bias, 32 had unclear risk of bias, and 545 had high risk of bias.
- The most common causes for high risk of bias were inadequate sample sizes (n=408, 67%) and inappropriate or incomplete evaluation of model performance (n=338, 56%).
- 381 models were newly developed, and 225 were external validations of existing models.
- The reported C indexes varied between 0.77 and 0.93 in development studies with low risk of bias, and between 0.56 and 0.78 in external validations with low risk of bias.
- The Qcovid models, the PRIEST score, Carr’s model, the ISARIC4C Deterioration model, and the Xie model showed adequate predictive performance in studies at low risk of bias.
- Details on all reviewed models are publicly available at https://www.covprecise.org/.
Conclusion
- Prediction models for covid-19 entered the academic literature to support medical decision making at unprecedented speed and in large numbers.
- Most published prediction model studies were poorly reported and at high risk of bias such that their reported predictive performances are probably optimistic.
- Models with low risk of bias should be validated before clinical implementation, preferably through collaborative efforts to also allow an investigation of the heterogeneity in their performance across various populations and settings.
- Methodological guidance, as provided in this paper, should be followed because unreliable predictions could cause more harm than benefit in guiding clinical decisions.
- Finally, prediction modellers should adhere to the TRIPOD (transparent reporting of a multivariable prediction model for individual prognosis or diagnosis) reporting guideline.
BOX 1: Availability of models in format for use in clinical practice
Three hundred and eighty one unique prognostic models were developed in the included studies.
Eighty (21%) of these models were presented as a model equation including intercept and regression coefficients.
Thirty nine (10%) models were only partially presented (eg, intercept or baseline hazard were missing).
The remaining 262 (69%) did not provide the underlying model equation.
One hundred and sixty one (42%) were available in a tool to facilitate use in clinical practice (in addition to or instead of a published equation).
Sixty models (16%) were presented as a nomogram, 35 (9%) as a web calculator, 30 (8%) as a sum score, nine (2%) as a software object, five (1%) as a decision tree or set of predictions for subgroups, and 22 (6%) in other usable formats (6%).
All these presentation formats make predictions readily available for use in the clinic.
However, because most of these prognostic models were at high or uncertain risk of bias, we do not recommend their routine use before they are externally validated, ideally by independent investigators in other data than used for their development.
…because most of these prognostic models were at high or uncertain risk of bias, we do not recommend their routine use before they are externally validated, ideally by independent investigators in other data than used for their development.
Infographic
Box 2 — PROBAST (prediction model risk of bias assessment tool) risk of bias for all included models combined (n=606) and broken down per type of analysis
REFERENCE PUBLICATION

Prediction models for diagnosis and prognosis of covid-19: systematic review and critical appraisal
Introduction
The novel coronavirus disease 2019 (covid-19) presents an important threat to global health. Since the outbreak in early December 2019 in the Hubei province of the People’s Republic of China, the number of patients confirmed to have the disease has exceeded 500 million as the disease spread globally, and the number of people infected is probably much higher. More than 6 million people have died from covid-19 (up to 24 May 2022).1 Despite public health responses aimed at containing the disease and delaying the spread, countries have been confronted with repeated surges disrupting health services23456 and society at large. More recent outbreaks of the omicron variant led to important increases in the demand for test capacity, hospital beds, and medical equipment, while medical staff members also increasingly became infected themselves.6 While many national governments have now put an end to covid-19 restrictions, scientists warn that endemic circulation of SARS-CoV-2, perhaps with seasonal epidemic peaks, is likely to have a continued important disease burden.7 In addition, virus mutations can be unpredictable, and lack of effective surveillance or adequate response could enable the emergence of new epidemic or pandemic covid-19 patterns.78 To mitigate the burden on the healthcare system, while also providing the best possible care for patients, reliable prognosis of covid-19 remains important to inform decisions regarding shielding, vaccination, treatment, and hospital or intensive care unit (ICU) admission. Prediction models that combine several variables or features to estimate the risk of people being infected or experiencing a poor outcome from the infection could assist medical staff in triaging patients when allocating limited healthcare resources.
The outbreak of covid-19 was accompanied by a surge of scientific evidence.9 The speed with which evidence about covid-19 has accumulated is unprecedented. To provide an overview of available prediction models, a living systematic review, with periodic updates, was conducted by the international covid-PRECISE (Precise Risk Estimation to optimise covid-19 Care for Infected or Suspected patients in diverse sEttings; https://www.covprecise.org/) group in collaboration with the Cochrane Prognosis Methods Group. Initially, the review included diagnostic and prognostic models. Owing to the current availability of testing for covid-19 infections, we restricted the focus to prognostic models in this new update. Hence our aim was to systematically review and critically appraise available prognostic models for detecting people in the general population at increased risk of covid-19 infection or being admitted to hospital or dying with the disease, and models to predict the prognosis or course of infection in patients with a covid-19 diagnosis. We included all prognostic model development and external validation studies.

Methods
We searched the publicly available, continuously updated publication list of the covid-19 living systematic review.10 We validated whether the list is fit for purpose (online supplementary material) and further supplemented it with studies on covid-19 retrieved from arXiv. The online supplementary material presents the search strings. We included studies if they developed or validated a multivariable model or scoring system, based on individual participant level data, to predict any covid-19 related outcome. These models included prognostic models to predict the course of infection in patients with covid-19; and prediction models to identify people in the general population at risk of covid-19 infection or at risk of being admitted to hospital or dying with the disease. Diagnostic models to predict the presence or severity of covid-19 in patients with suspected infection were included up to update 3 only, which can be found in the data supplements.
We searched the database repeatedly up to 17 February 2021 (supplementary table 1). As of the third update (search date 1 July 2020), we only include peer reviewed articles (indexed in PubMed and Embase through Ovid). Preprints (from bioRxiv, medRxiv, and arXiv) that were already included in previous updates of the systematic review remained included in the analysis. Reassessment took place after publication of a preprint in a peer reviewed journal and replaced the original assessment. No restrictions were made on the setting (eg, inpatients, outpatients, or general population), prediction horizon (how far ahead the model predicts), included predictors, or outcomes. Epidemiological studies that aimed to model disease transmission or fatality rates, and predictor finding studies, were excluded. We only included studies published in English. Starting with the second update, retrieved records were initially screened by a text analysis tool developed using artificial intelligence to prioritise sensitivity (supplementary material). Titles, abstracts, and full texts were screened for eligibility in duplicate by independent reviewers (pairs from LW, BVC, MvS, and KGMM) using EPPI-Reviewer,11 and discrepancies were resolved through discussion.
Data extraction of included articles was done by two independent reviewers (from LW, BVC, GSC, TPAD, MCH, GH, KGMM, RDR, ES, LJMS, EWS, KIES, CW, AL, JM, TT, JAD, KL, JBR, LH, CS, MS, MCH, NS, NK, SMJvK, JCS, PD, CLAN, RW, GPM, IT, JYV, DLD, JW, FSvR, PH, VMTdJ, BCTvB, ICCvdH, DJM, MK, BL, EA, SG, BA, JH, KJ, SG, KR, JE, MH, VB, and MvS). Reviewers used a standardised data extraction form based on the CHARMS (critical appraisal and data extraction for systematic reviews of prediction modelling studies) checklist12 and PROBAST (prediction model risk of bias assessment tool; https://www.probast.org/) for assessing the reported prediction models.1314 We sought to extract each model’s predictive performance by using whatever measures were presented. These measures included any summaries of discrimination (the extent to which predicted risks discriminate between participants with and without the outcome), and calibration (the extent to which predicted risks correspond to observed risks) as recommended in the TRIPOD (transparent reporting of a multivariable prediction model for individual prognosis or diagnosis; https://www.tripod-statement.org/) statement.1516 Discrimination is often quantified by the C index (C index=1 if the model discriminates perfectly; C index=0.5 if discrimination is no better than chance). Calibration is often assessed graphically using calibration plots or quantified by the calibration intercept (which is zero when the risks are not systematically overestimated or underestimated) and calibration slope (which is one if the predicted risks are not too extreme or too moderate).17 We focused on performance statistics as estimated from the strongest available form of validation (in order of strength: external (evaluation in an independent database), internal (bootstrap validation, cross validation, random training test splits, temporal splits), apparent (evaluation by using exactly the same data used for development)). Any discrepancies in data extraction were discussed between reviewers, and remaining conflicts were resolved by LW or MvS. The online supplementary material provides details on data extraction. Some studies investigated multiple models and some models were investigated in multiple studies (that is, in external validation studies). The unit of analysis was a model within a study, unless stated otherwise. We considered aspects of PRISMA (preferred reporting items for systematic reviews and meta-analyses)18 and TRIPOD1516 in reporting our study. Details on all reviewed studies and prediction models are publicly available at https://www.covprecise.org/.
Patient and public involvement
Severe covid-19 survivors and lay people participated by discussing their perspectives, providing advice, and acting as partners in writing a lay summary of the project’s aims and results (available at https://www.covprecise.org/project/), thereby taking part in the implementation of knowledge distribution. Owing to the initial emergency situation of the covid-19 pandemic, we did not involve patients or the public in the design and conduct of this living review in March 2020, but the study protocol and preliminary results were immediately publicly available on https://osf.io/ehc47/, medRxiv, and https://www.covprecise.org/living-review/.
Results
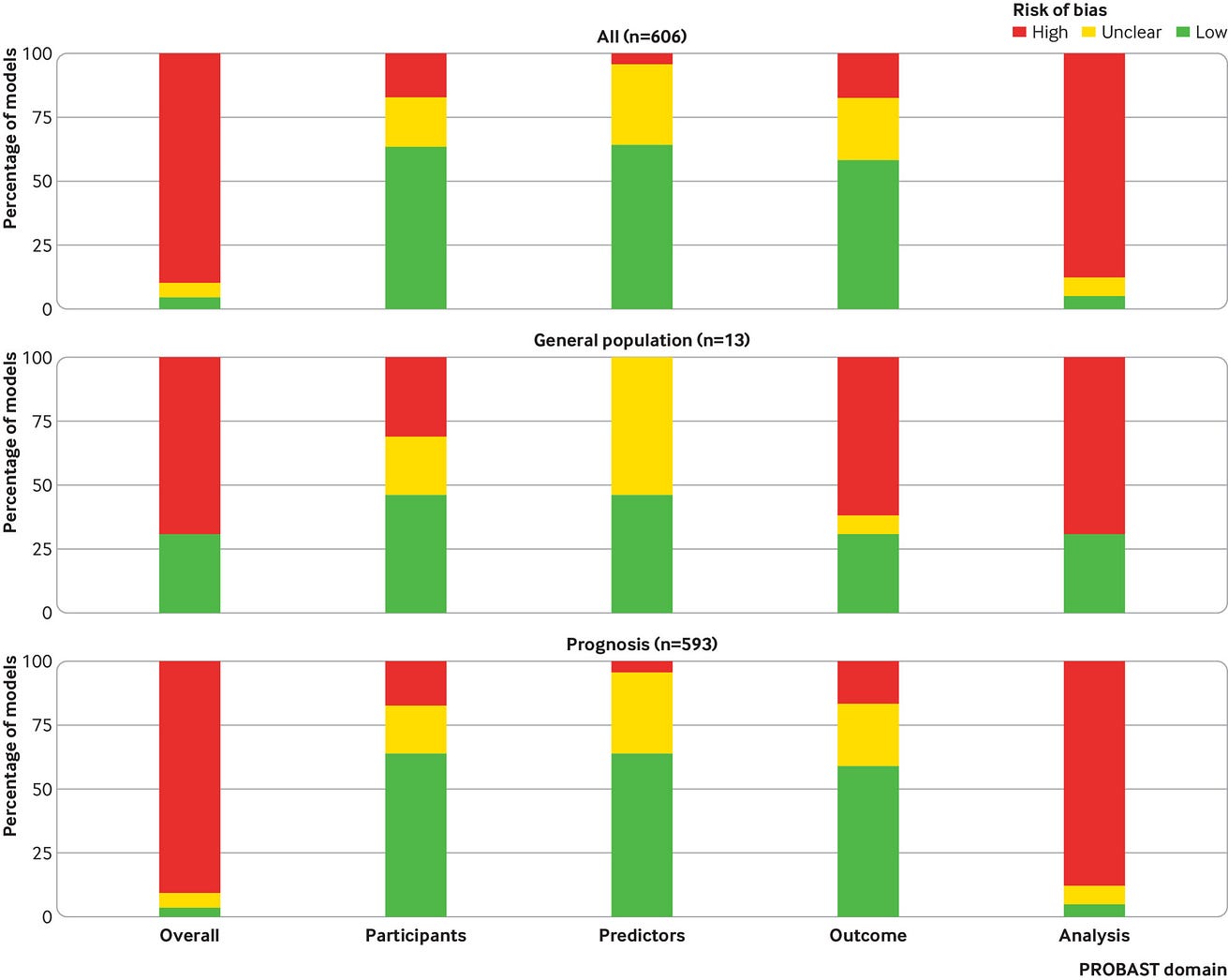
We identified 126 969 records through our systematic search, of which 89 566 were identified in the present search update (supplementary table 1, fig 1). We included a further nine studies that were publicly available but were not detected by our search. Of 126 978 titles, 828 studies were retained for abstract and full text screening. We included 412 studies describing 731 prediction models or validations, of which 243 studies with 499 models or validations were newly included in the present update (supplementary table)
Of these, 310 studies describing 606 prognostic models or validations of prognostic models are included in the current analysis: 13 prognostic models for developing covid-19 in the general population and 593 prognostic models for predicting outcomes in patients with covid-19 diagnoses. The results from previous updates, including diagnostic models, are available as supplementary material. A database with the description of each model and validation and its risk of bias assessment can be found on https://www.covprecise.org/.
Fig 1 — PRISMA (preferred reporting items for systematic reviews and meta-analyses) flowchart of study inclusions and exclusions
Of the 606 prognostic models, 381 were unique, newly developed models for covid-19, and 225 were external validations of existing models in a study other than the model development study. These external validations include external validations of newly developed covid models, as well as prognostic scores predating the covid-19 pandemic. Some models were validated more than once (in different studies, as described below). One hundred and fifty eight (41%) newly developed models were publicly available in a format for use in practice (box 1).
BOX 1: Availability of models in format for use in clinical practice
Three hundred and eighty one unique prognostic models were developed in the included studies.
Eighty (21%) of these models were presented as a model equation including intercept and regression coefficients.
Thirty nine (10%) models were only partially presented (eg, intercept or baseline hazard were missing).
The remaining 262 (69%) did not provide the underlying model equation.
One hundred and sixty one (42%) were available in a tool to facilitate use in clinical practice (in addition to or instead of a published equation).
Sixty models (16%) were presented as a nomogram, 35 (9%) as a web calculator, 30 (8%) as a sum score, nine (2%) as a software object, five (1%) as a decision tree or set of predictions for subgroups, and 22 (6%) in other usable formats (6%).
All these presentation formats make predictions readily available for use in the clinic.
However, because most of these prognostic models were at high or uncertain risk of bias, we do not recommend their routine use before they are externally validated, ideally by independent investigators in other data than used for their development.
…because most of these prognostic models were at high or uncertain risk of bias, we do not recommend their routine use before they are externally validated, ideally by independent investigators in other data than used for their development.
Primary datasets
Five hundred and fifty six (92%) developed or validated models used data from a single country ( table 1), 39 (6%) used international data, and for 11 (2%) models it was unclear how many (and which) countries contributed data. Three (0.5%) models used simulated data and 21 (3%) used proxy data to estimate covid-19 related risks (eg, Medicare claims data from 2015 to 2016). Most models were intended for use in confirmed covid-19 cases (83%) and a hospital setting (82%). The average patient age ranged from 38 to 84 years, and the proportion of men ranged from 1% to 95%, although this information was often not reported.
Based on the studies that reported study dates, data were collected from December 2019 to October 2020. Some centres provided data to multiple studies and it was unclear how much these datasets overlapped across identified studies.
The median sample size for model development was 414, with a median number of 74 individuals experiencing the event that was predicted. The mortality risk in patients admitted to hospital ranged from 8% to 46%. This wide variation is partly due to differences in length of follow-up between studies (which was often not reported), local and temporal variation in diagnostic criteria, admission criteria and treatment, as well as selection bias (eg, excluding participants who had neither recovered nor died at the end of the study period).
Models to predict covid-19 related risks in the general population
We identified 13 newly developed models aiming to predict covid-19 related risks in the general population.
Five models predicted hospital admission for covid-19, three predicted mortality, one predicted development of severe covid-19, and four predicted an insufficiently defined covid-19 outcome. Eight of these 13 general population models used proxy outcomes (eg, admission for non-tuberculosis pneumonia, influenza, acute bronchitis, or upper respiratory tract infections instead of hospital admission for covid-19). 20 The 13 studies reported C indexes between 0.52 and 0.99. Calibration was assessed for only four models, all in one study, which found slight miscalibration. 231
Prognostic models for outcomes in patients with diagnosis of covid-19
We identified 593 prognostic models for predicting clinical outcomes in patients with covid-19 (368 developments, 225 external validations).
These models were primarily for use in patients admitted to hospital with a proven diagnosis of covid-19 (n=496, 84%), but a specific intended use (ie, when exactly or at which moment in the investigation to use them, and for whom) was often not clearly described. Of these 593 prognostic models, 265 (45%) estimated mortality risk, 84 (14%) predicted progression to a severe or critical disease, and 53 (9%) predicted ICU admission. The remaining 191 studies used other outcomes (single or as part of a composite) including need for intubation, (duration of) mechanical ventilation, oxygen support, acute respiratory distress syndrome, septic shock, cardiovascular complications, (multiple) organ failure, and thrombotic complication, length of hospital stay, recovery, hospital admission or readmission, or length of isolation period. Prediction horizons varied between one day and 60 days but were often unspecified (n=387, 65%). Some studies (n=13, 2%) used proxy outcomes. For example, one study used data from 2015 to 2019 to predict mortality and prolonged assisted mechanical ventilation (as a non-covid-19 proxy outcome). 119
The studies reported C indexes between 0.49 and 1, with a median of 0.81 (interquartile range 0.75–0.89). The median C index was 0.83 for the mortality models, 0.83 for progression models, and 0.77 for ICU admission models. Researchers showed calibration plots for only 152 of the 593 models (26%, of which 102 at external validation). The calibration results were mixed, with several studies indicating inaccurate risk predictions (examples in Xie et al, 19 Barda et al, 73 and Zhang et al 122). Plots were sometimes constructed in an unclear way, hampering interpretation (examples in Guo et al, 89 Gong et al, 125 and Knight et al 147).
Risk of bias
Seven newly developed prognostic models and 22 external validations of prognostic models were at low risk of bias (n=29, 5%).
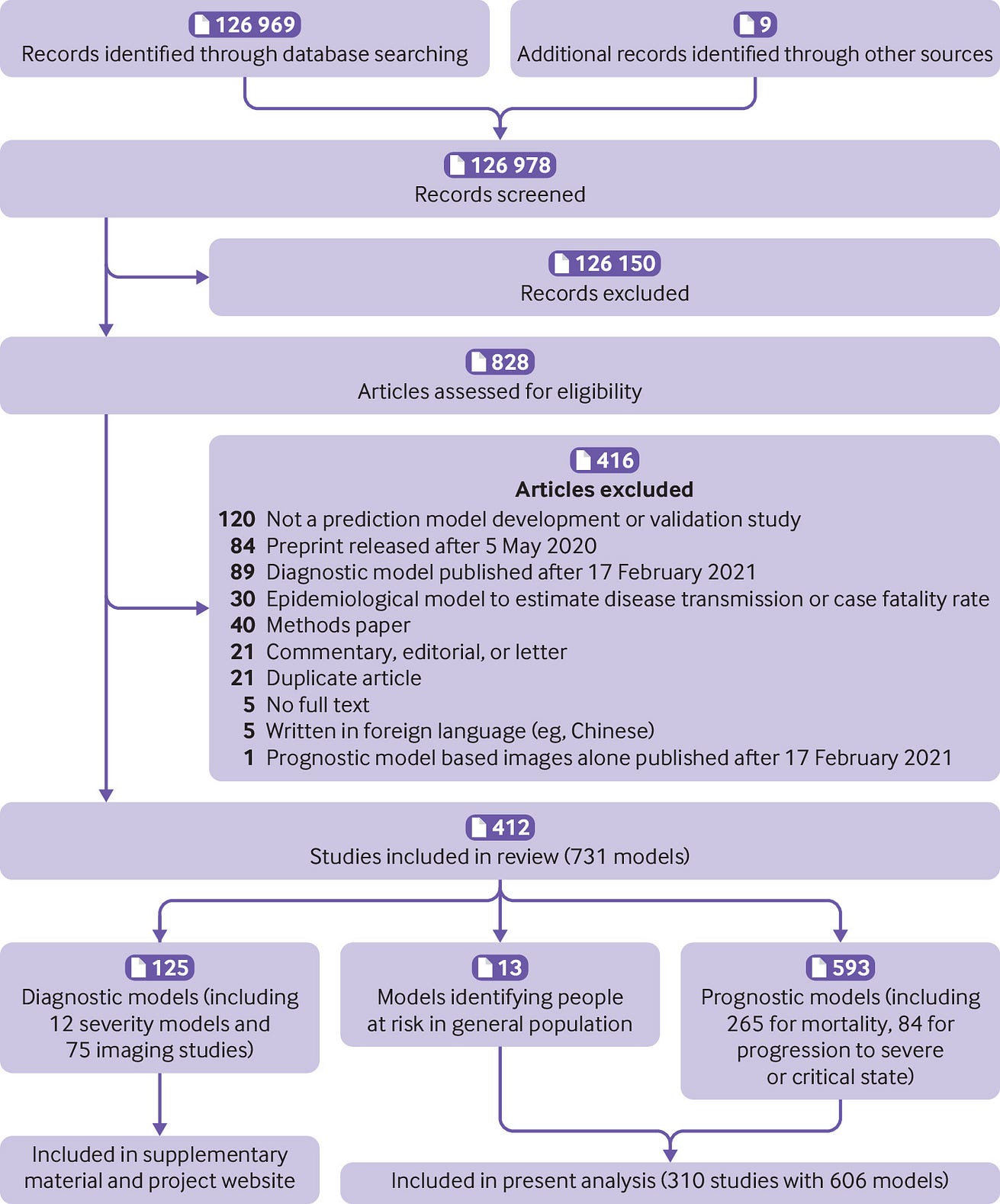
Most newly developed models and external validations were at unclear (n=32, 5%) or high (n=545, 90%) risk of bias according to assessment with PROBAST, which suggests that the predictive performance when used in practice is probably lower than what is reported ( fig 2). Figure 2 and box 2 give details on common causes for risk of bias.
Box 2 — PROBAST (prediction model risk of bias assessment tool) risk of bias for all included models combined (n=606) and broken down per type of analysis
Three hundred and eighty four (63%) of the 606 models and validations had a low risk of bias for the participants domain. One hundred and seven models (18%) had a high risk of bias for the participants domain, which indicates that the participants enrolled in the studies might not be representative of the models’ targeted populations. Unclear reporting on the inclusion of participants led to an unclear risk of bias assessment in 115 models (19%). Three hundred and eighty six models (64%) had a low risk of bias for the predictor domain, while 193 (32%) had an unclear risk of bias and 27 had a high risk of bias (4%). High risk of bias for the predictor domain indicates that predictors were not available at the models’ intended time of use, not clearly defined, or influenced by the outcome measurement. Most studies used outcomes that are easy to assess (eg, all cause death), and hence 353 (58%) were rated at low risk of bias for the outcome domain. Nonetheless, there was cause for concern about bias induced by the outcome measurement in 106 models (17%), for example, due to the use of proxy outcomes (eg, hospital admission for non-covid-19 severe respiratory infections). One hundred and forty seven (24%) had an unclear risk of bias due to opaque or ambiguous reporting. In contrast to the participant, predictor, and outcome domains, the analysis domain was problematic for most of the 606 models and validations. Overall, 530 (87%) were at high risk of bias for the analysis domain, and the reporting was insufficiently clear to assess risk of bias in the analysis in 42 (7%). Only 34 (6%) were at low risk of bias for the analysis domain.
Newly developed models at low risk of bias
We found seven newly developed models at low risk of bias ( table 2). All had good to excellent discrimination, but calibration varied, highlighting the need of local and temporal recalibration.
The four Qcovid models predict hospital admission and death with covid-19 in the general population in the UK, separately for men and women. 231 The models use age, ethnic group, deprivation, body mass index, and a range of comorbidities as predictors. The models showed underestimated risks for high risk patients at external validation, which was remedied by recalibrating the model. 231
The PRIEST score 262 predicts 30 day death or organ support in patients with suspected or confirmed covid-19 presenting at the emergency department. The triage score is based on NEWS2 (national early warning score 2 consisting of respiratory rate, oxygen saturation, heart rate, systolic blood pressure, temperature, consciousness, air, or supplemental oxygen), age, sex, and performance status (ranging from bed-bound to normal performance). Its external validation in UK emergency departments showed reasonable calibration, but potential heterogeneity in calibration across centres was not examined.
Carr’s model 81 and the ISARIC 4C deterioration model 268 predict deterioration in covid-19 patients admitted to hospital. The composite outcomes for both models included ICU admission and death, while the ISARIC 4C model also adds ventilatory support. Both models had comparable performance but included different predictors, all typically available at admission. Carr and colleagues supplemented NEWS2 with age, laboratory and physiological parameters (supplemental oxygen flow rate, urea, oxygen saturation, C reactive protein, estimated glomerular filtration rate, neutrophil count, neutrophil-lymphocyte ratio). Gupta and colleagues 268 developed a model including age, sex, nosocomial infection, Glasgow coma scale score, peripheral oxygen saturation at admission, breathing room air or oxygen therapy, respiratory rate, urea concentration, C reactive protein concentration, lymphocyte count, and presence of radiographic chest infiltrates. Carr’s model was validated internationally 81 and the ISARIC4C Deterioration model was validated regionally within the UK. 268 For both models, calibration varied across settings.
External validations at low risk of bias
We identified 225 external validations in dedicated (ie, not combined with the development of the model) external validation studies. Only 22 were low risk of bias, although all 22 validations came from the same study using single-centre UK data ( table 3). 269 This validation study included 411 patients, of which 180 experienced a deterioration in health, and 115 died. In this study, the Carr model and NEWS2 performed best to predict deterioration, while the Xie model and REMS performed best to predict mortality. Both the Carr model (a preprint version that differs slightly from the Carr model reported above) and the Xie model showed slight miscalibration.
NEWS2 and REMS were also validated in other dedicated validation studies. NEWS2 obtained C indexes between 0.65 and 0.90. 141203214233245280281303319340 REMS obtained C indexes between 0.74 and 0.88. 91233319 These studies were too heterogeneous and biased to meta-analyse: they used varying outcome definitions (mortality, ICU admission, various composites, with time horizons varying from 1 to 30 days), from different populations (Italy, UK, Norway, China), and were at high or unclear risk of bias.
Challenges and opportunities
The main aim of prediction models is to support medical decision making in individual patients. Therefore, it is vital to identify a target setting in which predictions serve a clinical need (eg, emergency department, intensive care unit, general practice, symptom monitoring app in the general population), and a representative dataset from that setting (preferably comprising consecutive patients) on which the prediction model can be developed and validated. This clinical setting and patient characteristics should be described in detail (including timing within the disease course, the severity of disease at the moment of prediction, and the comorbidity), so that readers and clinicians are able to understand if the proposed model is suited for their population. However, the studies included in our systematic review often lacked an adequate description of the target setting and study population, which leaves users of these models in doubt about the models’ applicability. Although we recognise that the earlier studies were done under severe time constraints, we recommend that researchers adhere to the TRIPOD reporting guideline 1516 to improve the description of their study population and guide their modelling choices. TRIPOD translations (eg, in Chinese) are also available at https://www.tripod-statement.org. A better description of the study population could also help us understand the observed variability in the reported outcomes across studies, such as covid-19 related mortality. The variability in mortality could be related to differences in included patients (eg, age, comorbidities) but also in interventions for covid-19.
In this living review, inadequate sample size to build a robust model or to obtain reliable performance statistics was one of the most prevalent shortcomings. We recommend researchers should make use of formulas and software that have been made available in recent years to calculate the required sample size to build or externally validate models. 439440441442 The current review also identified that ignoring missing data and performing a complete case analysis is still very common. As this leads to reduced precision and can introduce bias in the estimated model, we recommend researchers address missing data using appropriate techniques before developing or validating a model. 443444 When creating a new prediction model, we recommend building on previous literature and expert opinion to select predictors, rather than selecting predictors purely based on data. 17 This recommendation is especially important for datasets with limited sample size. 445 To temper optimism in estimated performance, several internal validation strategies can be used-for example, bootstrapping. 17446 We also recommend that researchers should evaluate model performance in terms of correspondence between predicted and observed risk, preferably using flexible calibration plots 17447 in addition to discrimination.
Covid-19 prediction will often not present as a simple binary classification task. Complexities in the data should be handled appropriately. For example, a prediction horizon should be specified for prognostic outcomes (eg, 30 day mortality). If study participants neither recovered nor died within that period, their data should not be excluded from analysis, which some reviewed studies have done. Instead, an appropriate time-to-event analysis should be considered to allow for administrative censoring. 17 Censoring for other reasons, for instance because of quick recovery and loss to follow-up of patients who are no longer at risk of death from covid-19, could necessitate analysis in a competing risk framework. 448
A prediction model applied in a new healthcare setting or country often produces predictions that are miscalibrated 447 and might need to be updated before it can safely be applied in that new setting. 17 This requires data from patients with covid-19 to be available from that setting. In addition to updating predictions in their local setting, individual participant data from multiple countries and healthcare systems might allow better understanding of the generalisability and implementation of prediction models across different settings and populations. This approach could greatly improve the applicability and robustness of prediction models in routine care. 446449450451452
The covid-19 pandemic has been characterised by an unprecedented speed of data accumulation worldwide. Unfortunately, much of the work done to analyse all these data has been ill informed and disjointed. As a result, we have hundreds of similar models, and very few independent validation studies comparing their performance on the same data. To leverage the full potential of prediction models in emerging pandemics and quickly identify useful models, international and interdisciplinary collaboration in terms of data acquisition, model building, model validation, and systematic review is crucial.
Study limitations
With new publications on covid-19 related prediction models entering the medical literature in unprecedented numbers and at unprecedented speed, this systematic review cannot be viewed as an up-to-date list of all currently available covid-19 related prediction models. It does provide a comprehensive overview of all prognostic model developments and validations from the first year of the pandemic up to 17 February 2021. Also, 69 of the studies we reviewed were only available as preprints. Some of these studies might enter the official medical literature in an improved version, after peer review. We reassessed peer reviewed publications of preprints included in previous updates that have been published before the current update. We also found other prediction models have been used in clinical practice without scientific publications, 453 and web risk calculators launched for use while the scientific manuscript is still under review (and unavailable on request). 454 These unpublished models naturally fall outside the scope of this review of the literature. As we have argued extensively elsewhere, 455 transparent reporting that enables validation by independent researchers is key for predictive analytics, and clinical guidelines should only recommend publicly available and verifiable algorithms.
Implications for practice
This living review has identified a handful of models developed specifically for covid-19 prognosis with good predictive performance at external validation, and with model development or external validation at low risk of bias. The Qcovid models 231 were built to prognosticate hospital admission and mortality risks in the general population. The PRIEST model was proposed to triage patients at the emergency department. 262 The ISARIC4C Deterioration model, 268 Carr model, 81 and Xie model 19269 were developed to predict adverse outcomes in hospitalised patients (ventilatory support, critical care or death, ICU admission or death, and death, respectively). Since the search date, these models have been validated temporally and geographically, which demonstrated that care should be taken when using these models in policy or clinical practice. 231268456457458459460 Differences between healthcare systems, fluctuations in infection rates, virus mutations, differences in vaccination status, varying testing criteria, and changes in patient management and treatment can lead to miscalibration in more recent or local data. Hence, future studies should focus on validating and comparing these prediction models with low risk of bias. 17 External validations should not only assess discrimination, but also calibration and clinical usefulness (net benefit), 447452461 in large studies 439440442462463 using an appropriate design.
Many prognostic models have been developed for prognostication in a hospital setting. Updating an available model to accommodate temporal or regional differences or extending an existing model with new predictors requires less data and provides generally more robust predictions than developing a new prognostic model. 17 New variants could vary in contagiousness and severity, and vaccination and waning immunity might alter individual risks. Consequently, even updated models could become outdated. These changes would primarily affect calibration (ie, absolute risk estimates might be too high or too low), while the discrimination between low and high risk patients could be less affected. Miscalibration is especially concerning for general population models. Models that focus on patients seeking care and adjust risk estimates for symptoms and severity markers might be more robust, but this hypothesis remains to be confirmed empirically.
Although many models exist to predict outcomes at the emergency department or at hospital admission, few are suited for patients with symptoms attending primary care, or for patients admitted to the ICU. In addition, the models reviewed so far focus on the covid-19 diagnosis or assess the risk of mortality or deterioration, whereas long term morbidity and functional outcomes remain understudied and could be a target outcome of interest in future studies developing prediction models. 464465
This review of prediction models developed in the first year of the covid-19 pandemic found most models at unclear or high risk of bias. Whereas many external validations were done, most were at high risk of bias and most models developed specifically for covid-19 were not validated independently. This oversupply of insufficiently validated models is not useful for clinical practice. Moreover, the urgency of diagnostic and prognostic models to assist in quick and efficient triage of patients in an emergent pandemic might encourage clinicians and policymakers to prematurely implement prediction models without sufficient documentation and validation. Inaccurate models could even cause more harm than good. 461 By pointing to the most important methodological challenges and issues in design and reporting, we hope to have provided a useful starting point for future studies and future epidemics.
Conclusion
Several prognostic models for covid-19 are currently available and most report moderate to excellent discrimination.
However, many of these models are at high or unclear risk of bias, mainly because of model overfitting, inappropriate model evaluation (eg, calibration ignored), and inappropriate handling of missing data.
Therefore, their performance estimates are probably optimistic and might not be representative for the target population.
We found that the Qcovid models can be used for risk stratification in the general population, while the PRIEST model, ISARIC4C Deterioration model, Carr’s model, and Xie’s model are suitable for prognostication in a hospital setting.
The performance of these models is likely to vary over time and differ between regions, necessitating further validation and potentially updating before implementation.
For details of the reviewed models, see https://www.covprecise.org/. Sharing data and expertise for the validation and updating of covid-19 related prediction models is still needed.
Originally published at https://www.bmj.com on April 7, 2020.
About the authors & affiliations
Laure Wynants, assistant professor 1 2,
Ben Van Calster, associate professor2 3,
Gary S Collins, professor4 5,
Richard D Riley, professor6,
Georg Heinze, associate professor7,
Ewoud Schuit, assistant professor8 9,
Elena Albu, doctoral student2,
Banafsheh Arshi, research fellow1,
Vanesa Bellou, postdoctoral research fellow10,
Marc M J Bonten, professor8 11,
Darren L Dahly, principal statistician12 13,
Johanna A Damen, assistant professor8 9,
Thomas P A Debray, assistant professor8 14,
Valentijn M T de Jong, assistant professor8 9,
Maarten De Vos, associate professor2 15,
Paula Dhiman, research fellow4 5,
Joie Ensor, research fellow6,
Shan Gao, doctoral student2,
Maria C Haller, medical doctor7 16,
Michael O Harhay, assistant professor17 18,
Liesbet Henckaerts, assistant professor19 20,
Pauline Heus, assistant professor8 9,
Jeroen Hoogland, statistician8,
Mohammed Hudda, senior research fellow21,
Kevin Jenniskens, assistant professor8 9,
Michael Kammer, research associate7 22,
Nina Kreuzberger, research associate23, Anna Lohmann24, Brooke Levis, postdoctoral research fellow6, Kim Luijken, doctoral candidate24, Jie Ma, medical statistician5, Glen P Martin, senior lecturer25, David J McLernon, senior research fellow26, Constanza L Andaur Navarro, doctoral student8 9, Johannes B Reitsma, associate professor8 9, Jamie C Sergeant, senior lecturer27 28, Chunhu Shi, research associate29, Nicole Skoetz, professor22, Luc J M Smits, professor1, Kym I E Snell, senior lecturer6, Matthew Sperrin, senior lecturer30, René Spijker, information specialist8 9 31, Ewout W Steyerberg, professor3, Toshihiko Takada, associate professor8 32, Ioanna Tzoulaki, assistant professor10 33, Sander M J van Kuijk, research fellow34, Bas C T van Bussel, medical doctor1 35, Iwan C C van der Horst, professor35, Kelly Reeve36, Florien S van Royen, research fellow8, Jan Y Verbakel, assistant professor37 38, Christine Wallisch, research fellow7 39 40, Jack Wilkinson, research fellow24,
Robert Wolff, medical doctor41, Lotty Hooft, professor8 9, Karel G M Moons, professor8 9,
Maarten van Smeden, associate professor8
1Department of Epidemiology, CAPHRI Care and Public Health Research Institute, Maastricht University, Maastricht, Netherlands
2Department of Development and Regeneration, KU Leuven, Leuven, Belgium
3Department of Biomedical Data Sciences, Leiden University Medical Centre, Leiden, Netherlands
4Centre for Statistics in Medicine, Nuffield Department of Orthopaedics, Musculoskeletal Sciences, University of Oxford, Oxford, UK
5NIHR Oxford Biomedical Research Centre, John Radcliffe Hospital, Oxford, UK
6Centre for Prognosis Research, School of Medicine, Keele University, Keele, UK
7Section for Clinical Biometrics, Centre for Medical Statistics, Informatics and Intelligent Systems, Medical University of Vienna, Vienna, Austria
8Julius Center for Health Sciences and Primary Care, University Medical Center Utrecht, Utrecht University, Utrecht, Netherlands
9Cochrane Netherlands, University Medical Center Utrecht, Utrecht University, Utrecht, Netherlands
10Department of Hygiene and Epidemiology, University of Ioannina Medical School, Ioannina, Greece
11Department of Medical Microbiology, University Medical Centre Utrecht, Utrecht, Netherlands
12HRB Clinical Research Facility, Cork, Ireland
13School of Public Health, University College Cork, Cork, Ireland
14Smart Data Analysis and Statistics BV, Utrecht, Netherlands
15Department of Electrical Engineering, ESAT Stadius, KU Leuven, Leuven, Belgium
16Ordensklinikum Linz, Hospital Elisabethinen, Department of Nephrology, Linz, Austria
17Department of Biostatistics, Epidemiology and Informatics, Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA, USA
18Palliative and Advanced Illness Research Center and Division of Pulmonary and Critical Care Medicine, Department of Medicine, Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA, USA
19Department of Microbiology, Immunology and Transplantation, KU Leuven-University of Leuven, Leuven, Belgium
20Department of General Internal Medicine, KU Leuven-University Hospitals Leuven, Leuven, Belgium
21Population Health Research Institute, St. George’s University of London, Cranmer Terrace, London, UK
22Department of Nephrology, Medical University of Vienna, Vienna, Austria
23Evidence-Based Oncology, Department I of Internal Medicine and Centre for Integrated Oncology Aachen Bonn Cologne Dusseldorf, Faculty of Medicine and University Hospital Cologne, University of Cologne, Cologne, Germany
24Department of Clinical Epidemiology, Leiden University Medical Centre, Leiden, Netherlands
25Division of Informatics, Imaging and Data Science, Faculty of Biology, Medicine and Health, Manchester Academic Health Science Centre, University of Manchester, Manchester, UK
26Institute of Applied Health Sciences, University of Aberdeen, Aberdeen, UK
27Centre for Biostatistics, University of Manchester, Manchester Academic Health Science Centre, Manchester, UK
28Centre for Epidemiology Versus Arthritis, Centre for Musculoskeletal Research, University of Manchester, Manchester Academic Health Science Centre, Manchester, UK
29Division of Nursing, Midwifery and Social Work, School of Health Sciences, University of Manchester, Manchester, UK
30Faculty of Biology, Medicine and Health, University of Manchester, Manchester, UK
31Amsterdam UMC, University of Amsterdam, Amsterdam Public Health, Medical Library, Netherlands
32Department of General Medicine, Shirakawa Satellite for Teaching And Research, Fukushima Medical University, Fukushima, Japan
33Department of Epidemiology and Biostatistics, Imperial College London School of Public Health, London, UK
34Department of Clinical Epidemiology and Medical Technology Assessment, Maastricht University Medical Centre+, Maastricht, Netherlands
35Department of Intensive Care Medicine, Maastricht University Medical Centre+, Maastricht University, Maastricht, Netherlands
36Epidemiology, Biostatistics and Prevention Institute, University of Zurich, Zurich, CH
37EPI-Centre, Department of Public Health and Primary Care, KU Leuven, Leuven, Belgium
38NIHR Community Healthcare Medtech and IVD cooperative, Nuffield Department of Primary Care Health Sciences, University of Oxford, Oxford, UK
39Charité Universitätsmedizin Berlin, corporate member of Freie Universität Berlin, Humboldt-Universität zu Berlin, Berlin, Germany
40Berlin Institute of Health, Berlin, Germany
41Kleijnen Systematic Reviews, York, UK
Notes
[1] Based on: “How Foundation Models Can Advance AI in Healthcare”, published by “HAI Stanford”, by “Jason Fries, Ethan Steinberg, Scott Fleming, Michael Wornow, Yizhe Xu, Keith Morse, Dev Dash, Nigam Shah”, on Dec 15, 2022