




Toyya Pujol, PhD
Purdue School of Engineering
August 6, 2021.
Credit to the image on top: analysis group
The healthcare industry in the United States is enormous.
In 2019, U.S. healthcare spending was $3.8 trillion — 17.7 percent of gross domestic product (GDP) and $11,518 per person, according to the Centers for Medicare & Medicaid Services.
This industry of patient care also is enormously complex, with the accumulated data of myriad patients, clinicians, support staff, and institutional providers including hospitals.
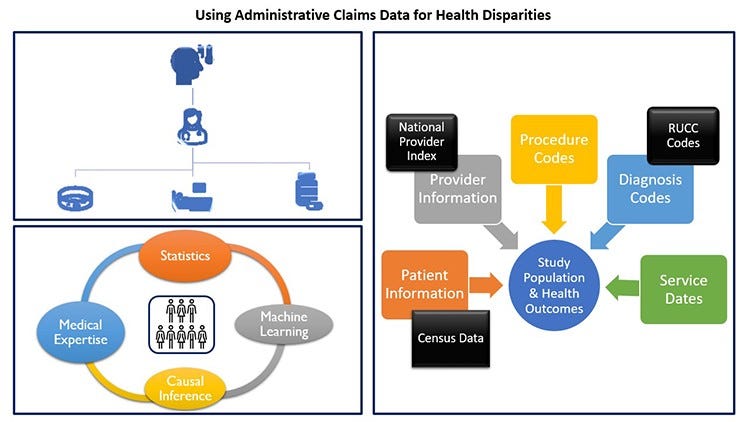
That’s where data science comes in. A multifaceted “system of systems,” healthcare benefits greatly from the use of data science tools — like analytics, machine learning, causal inference, and network science — to sort through all the data points to tease out trends and make recommendations that inform better policy and patient outcomes.
As an example, I work with administrative claims data to try to answer vital health questions.
Whenever you go to the doctor, a claim is sent to the insurer. That claim contains a ton of information — any procedure performed, any diagnosis made, the date of the service, the type of provider, and so forth.
Claims data is especially good for aggregate analysis, because there is so much of it — hundreds of millions of claims a year for the millions of people included in the dataset.
Claims data is particularly useful for analyzing policies, clinical interventions, and changes in trends.
For instance, in one study, I assessed the impact of the CDC’s U.S. Medical Eligibility Criteria for Contraception Use (MEC), a new contraception guideline for women with chronic health conditions.
The guidelines identified 20 medical conditions — such as hypertension, diabetes, epilepsy and HIV — that increase a woman’s risk for an adverse outcome in the event of an unplanned pregnancy.
To mitigate that risk, the MEC recommended long-acting, highly effective contraceptive methods (e.g., IUDs and implants).
In our study, employing data science methodologies and statistical analysis across a large dataset of 250,000 women, we found an increase in contraceptive use overall, but not in highly effective contraceptive methods across all conditions.
While my primary discipline is industrial engineering, I work closely with researchers in numerous other disciplines, including psychology, computer science, health care policy, and medicine.
I strive for my work to be impactful, and each of these collaborations, tapping interdisciplinary expertise, has uniquely supported the content relevance of my work. To achieve this goal, it is imperative to have a clinician on board to incorporate medical knowledge and the day-to-day limitations for a practicing clinician. Beyond merely undertaking data analysis projects, I identify differences or improvements that are both statistically and clinically significant.
I have started to incorporate information from census data, in order to better understand underserved populations, as well as the environment that contributes to their health (or health disparities), which may relate to race, class, gender, or the urban/rural divide.
Being able to bring in lots of different publicly available datasets and connect them is important for a fuller understanding of health outcomes.
For example, health disparities and their impact on labor productivity cost the European Union 1.4 percent of its GDP and cost hundreds of billions of dollars in the U.S. annually.
Considering the discrepancies in life expectancy, maternal and infant mortality, and access to quality healthcare, to name a few aspects, health inequity is also an ethical problem.
I explore the effects of inequity in the context of healthcare.
My research focuses on low-income, disabled, and chronically ill people.
I have learned how ZIP Code is one of the best predictors of health, how physician bias leads to lower-quality healthcare, and that medical issues are the primary cause of U.S. bankruptcies.
My interests stem from a desire to support vulnerable populations by deciphering the reasons why they are at risk.
As I continue to work in health data science, I am becoming aware of yet another manifestation of inequity: a greater threat to data privacy for underserved populations.
Data has become an increasingly valuable commodity, and the volume of data continues to grow. This growth endangers the security of sensitive healthcare data and the privacy of individuals included in these datasets.
Today, I already see the beginnings of a system in which privacy is a luxury good, driven by a gap between those who can pay for it and those who cannot.
This divergence leads to poorer populations being susceptible to dat a misuse, the most commonly known form of which is financial identity theft.
However, the idea of identity is evolving to include social and biomedical identities. Thus, identity protection must also consider mainstream technologies, such as those provided by Facebook and 23andMe.
Researchers are stewards of people’s data, so we need to make sure we maintain public trust, and continue to offer valuable findings in exchange for public support through data as well as taxpayer-funded research.
A closing thought: As AI tools become a bigger part of healthcare policy, it is important to note that we want them to supplement the clinician and policymaker, providing additional information to enable better decisions.
We need to ensure that these data science tools augment human decisions rather than replacing them.
We need to remain cognizant of the role and value of human intuition and interactions as we continue to conduct research and advance in this expanding area.
About the author
Toyya Pujol, PhD
Assistant Professor, School of Industrial Engineering and Member, College of Engineering, Purdue University Purdue Engineering Initiative in Data and Engineering Applications Regenstrief Center for Healthcare Engineering
Originally published at https://medium.com on August 6, 2021.







